Dans la vidéo d’aujourd’hui, on parle des méthodes de traitement du langage naturel, et comment les techniques de deep learning dominent aujourd’hui les algorithmes de traduction ou de complétion de texte.
L’idée de cette vidéo est née après celle sur Alpha Fold. J’y évoquai en passant les transformers, et je me suis dit qu’il fallait faire une vidéo sur ces fameux transformers ! Et puis en faisant la biblio et en écrivant la vidéo, je me suis dit que j’avais bien trop de trucs à raconter, donc à la fin je parle à peine des transformers ! Mais voici tout de même les considérations complémentaires d’usage
Pour commencer sur la terminologie, je suis resté évasif en employant de façon pas très formelle les termes d’algorithme, fonction, etc. Dire qu’un réseau de neurone est « un algorithme » peut être discuté. J’ai notamment totalement passé sous silence la question de l’entrainement des réseaux, qui est évidemment cruciale. Et c’est là d’ailleurs qu’on utilise un algorithme essentiel : la rétropropagation du gradient (back-propagation). D’ailleurs j’ai parlé de la dilution de la mémoire dans les réseaux récurrents, mais il y a le problème conjoint du gradient vanishing qui fait que la rétropropagation a du mal à être sensible à ce qu’il se passe dans les premières unités du réseau.
D’ailleurs pour ceux qui aiment les détails, une des raisons du problème c’est que quand le réseau utilise une fonction d’activation du genre sigmoïde ou tanh, il compresse le signal entre 0 et 1 ou -1 et 1. Et les compressions successives sont la raison de la déperdition de ce qui vient des premières unités récurrentes. L’astuce dans les LSTM est d’avoir une deuxième ligne de propagation d’information qui elle ne subit pas d’activation (\(c_t\) ci-dessous).
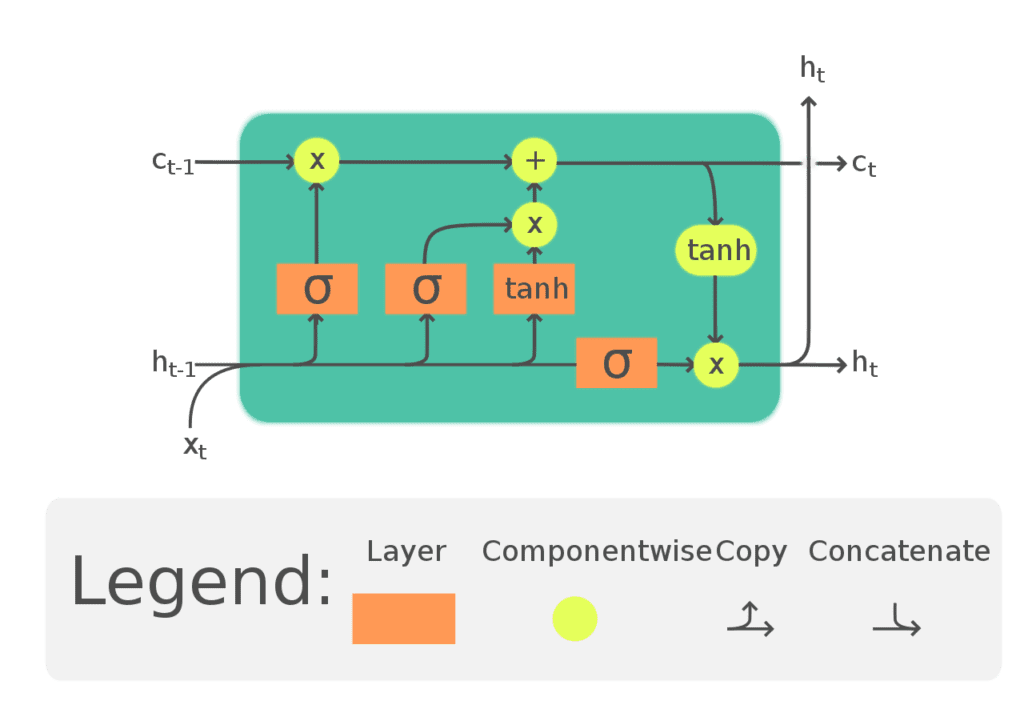
Word2Vec
A propos de Word2Vec et consorts, j’ai intentionellement passé sous silence la question de l’arithmétique des vecteurs. Et notamment les trucs du genre « roi – homme + femme = reine ». La raison est que j’ai testé sur GloVe, et ça ne marche pas si bien que ça ! Avec les données de GloVe, si on fabrique le vecteur « roi-homme+femme », on obtient un nouveau vecteur, et si on cherche le mot le plus proche de ce dernier, il s’agit de … roi !
Je me demande si un partie du problème ne vient pas du fait que la mesure de similarité est une « distance cosinus », c’est-à-dire le cosinus de l’angle entre les deux vecteurs. Le truc qui marche bien (et qui a été mis en avant par les chercheurs), c’est plutôt que le vecteur « roi-reine » est relativement bien parallèle au vecteur « homme-femme ».
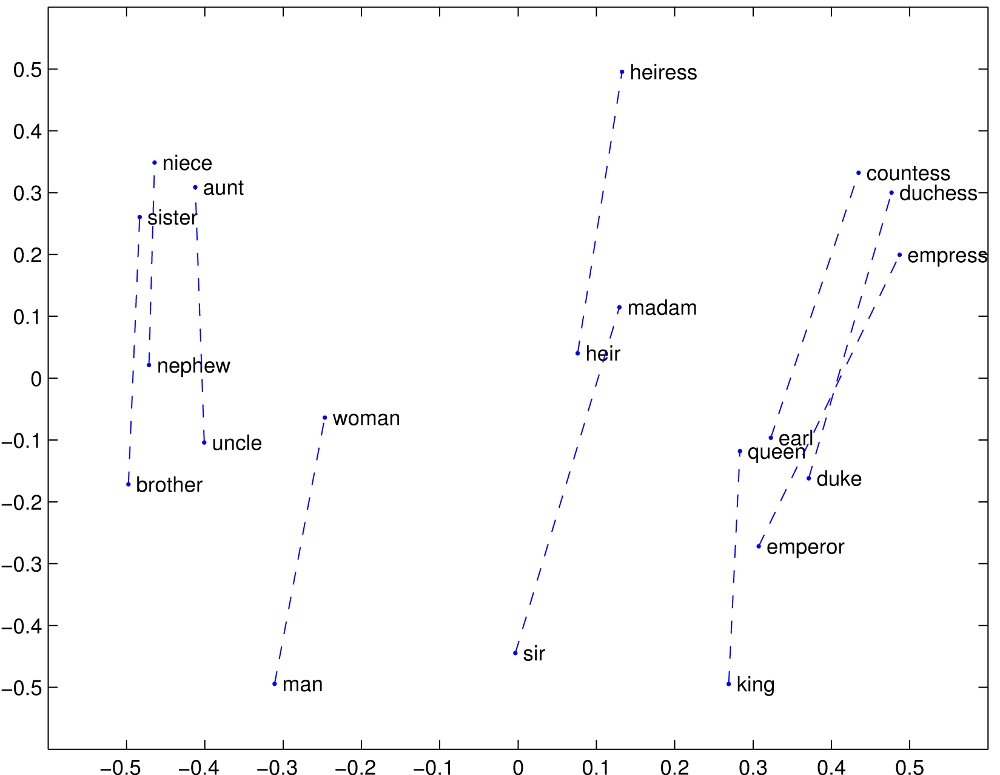
Un truc qu’on pourrait faire, c’est voir s’il n’y a pas un coefficient \(\alpha\) qui permet de faire en sorte que « roi + \(\alpha\)(femme-homme) » soit proche de « reine ».
Si j’ai le temps, je creuserai un jour ces questions d’arithmétique des vecteurs.
(En écrivant ce billet je découvre ce billet qui semble dire des choses analogues)
Autres applications
Par manque de temps, j’ai aussi zappé quelques applications super intéressantes comme la génération automatique de légendes (qui prend une image en entrée et sort un texte en sortie). Mais aussi les applications à d’autres domaines comme le traitement du son, de la musique, des séries temporelles en général.





10 Comments
Merci.
merci pour votre clarté , malgré un sujet si vaste et difficile.
Des compléments bibliographiques ( comme https://arxiv.org/pdf/2005.14165.pdf ) eussent été utiles ;
le presque-parallélisme des vecteurs évoque le mauvais conditionnement , mais vous dites que vous en re-parlerez ;
la représentation du monde (+ un moteur de raisonnement associé) manque à GPT3 , mais WuDao peut être ? ;
oui, la notion « porter de l’attention » paraît capitale ( ne pas diluer la mémoire ) , mais
le gigantisme de la RAM fait peur, notre cerveau paraît si économe par comparaison ;
tant de progrès en 5 ans sur les transformers et pourtant tant de questions malgré tout ,
sujet trop neuf ? à reprendre ?
merci encore
Bonjour David,
J’ai été surpris par le commentaire désobligeant qui apparaît dans cette vidéo vers 8:18
Avez-vous une idée de son origine?
Bonjour David,
Merci pour le billet et les références, super comme d’hab !
Food for thought concernant l’arithmétique des mots : Y a-t-il une raison pour que l’origine corresponde à la notion « de rien » ? Dans le cas contraire, peut-être qu’il faudrait trouver justement le vrai point « origine »correspondant au rien. Sinon, pour autant qu’on sache, quand on calcule « roi – homme + femme » on calcule peut-être en fait « roi – homme + femme + trottinette », et il n’y a pas de raison que ce soit le plus proche voisin de « reine ».
Bon, après il semblerait tout de même que reine ne soit pas bien loin de « roi – homme + femme » donc j’y crois moyen à mes histoires…
A 23’45, on apprend que GPT possède 175 milliards de poids (à ajuster pour chaque mot). C’est dingue, non ? Je n’ai rien à en dire sinon que ça donne le vertige. D’autant plus qu’avec tous ces poids le système est encore loin de comprendre vraiment ce qu’on lui donne à traiter.
Et merci beaucoup pour cette vidéo, comme j’utilise beaucoup DeepL ou Google, ma curiosité est satisfaite.
Pingback: Comment les IA font semblant de comprendre le langage humain ? – binaire
Pingback: Quand la machine reconnaît les visages - Finance&Gestion
Pingback: Diffuser ou rendre privées les données - Finance&Gestion
Pingback: ChatGPT ? Voulez-vous comprendre ce que c’est ? – binaire
Pingback: Diffuser ou rendre privées les données - Variances