La vidéo du jour explique quelques principes derrière les algorithmes d’IA générative qui fonctionnent selon les méthodes de diffusion.
Pour commencer, quelques références importantes sur le sujet. Tout d’abord l’article qui pour la première fois a proposé les méthodes de diffusion
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., & Ganguli, S. (2015, June). Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning (pp. 2256-2265). PMLR.
Le papier qui a démocratisé leur usage pour la génération d’image
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33, 6840-6851.
Et enfin plus récent, le papier derrière Stable Diffusion
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., & Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10684-10695).
avec en particulier le conditionnement par une classe ou l’embedding d’un texte.
Sur la façon dont les méthodes de diffusion se comparent à d’autres, ce papier de NVIDIA présente un graphique sous forme de « trilemme »
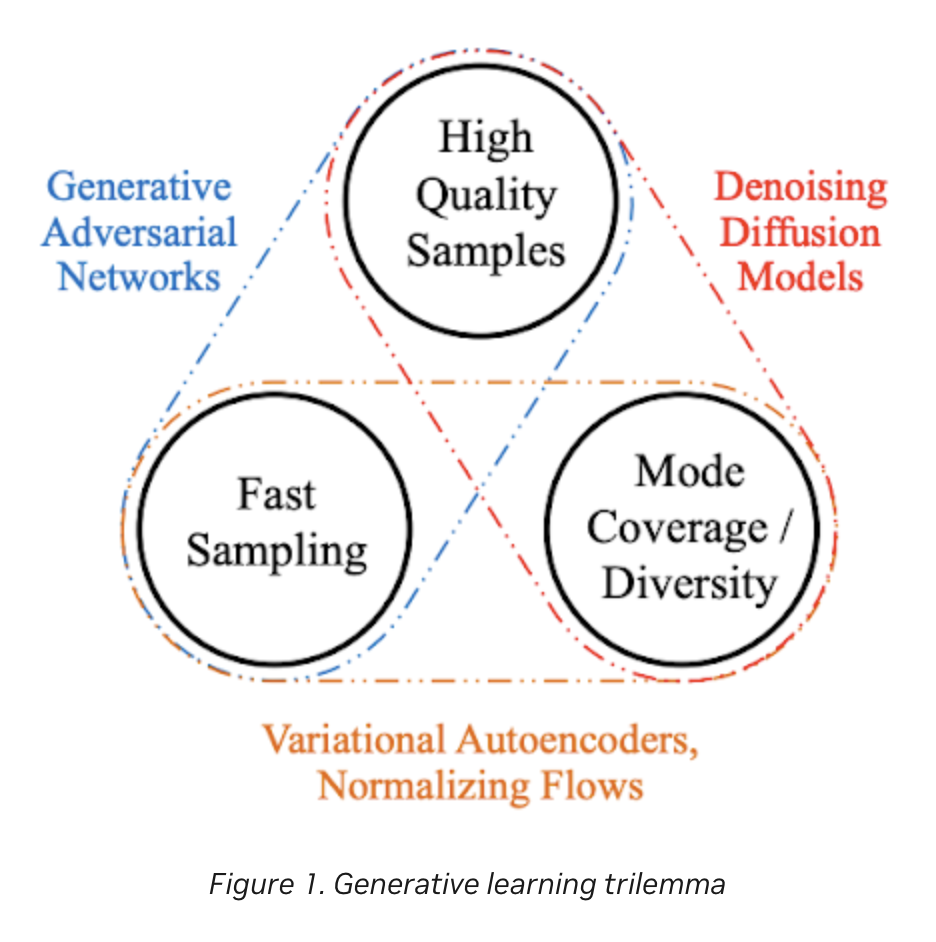 Une des force de Stable Diffusion est d’avoir réussi à obtenir la rapidité d’échantillonage qui manquait aux modèles de diffusion, notamment grâce à une astuce : réaliser le débruitage dans un « espace latent ».
Une des force de Stable Diffusion est d’avoir réussi à obtenir la rapidité d’échantillonage qui manquait aux modèles de diffusion, notamment grâce à une astuce : réaliser le débruitage dans un « espace latent ».
Diffusion dans l’espace latent
Voici en gros l’idée : si on veut des images de résolution raisonnable (disons 512×512), le processus d’échantillonage d’un modèle de diffusion classique prend du temps. La solution qu’ils ont imaginé est de faire ça sur une version « compressée » de l’image. On prend un bruit de 64×64, on réalise le débruitage, puis on « upscale » l’image d’un facteur 8 dans chaque dimension pour arriver sur 512×512. Evidemment pour que ça marche, il faut avoir entrainé l’algorithme de débruitage sur des version compressées des images de la base de données.
A ce stade, on pourrait penser que ce que j’appelle « compression » ou « upscaling » sont juste des redimensionnements simples des images. Mais non, l’idée est de les compresser dans un « espace latent » en utilisant un auto-encodeur variationnel (VAE). Il s’agit d’une famille d’algorithmes qui (en gros) compressent intelligemment des données en apprenant une représentation dans espace latent de plus faible dimension : je vous recommande cet excellent billet de Joseph Rocca sur le sujet).
Donc si on dispose d’un tel VAE entrainé sur les images de la base, on procède de la façon suivante : on encode les images, on entraine l’algorithme de débruitage sur les représentations encodées. Et quand on produit une image par débruitage, on la produit « dans l’espace latent », et à la fin on n’a plus qu’à la décoder.
C’est notamment cette étape de décodage qui explique que quand on utilise Stable Diffusion et qu’on s’amuse à regarder les étapes intermédiaires (quand tout le bruit n’a pas été encore retiré), on voit des images dont le « bruitage » ne ressemble pas à celui que j’ai représenté dans ma vidéo, mais plutôt à ça :
 qui est en gros un bruit gaussien de l’espace latent (64×64) qui a été upscalé par le decodeur du VAE pour produire une image 512×512.
qui est en gros un bruit gaussien de l’espace latent (64×64) qui a été upscalé par le decodeur du VAE pour produire une image 512×512.
Concernant DALL·E, je crois comprendre que la première version n’utilisait pas les algorithmes de diffusion (et marchait moyennement d’ailleurs), tandis que DALL·E 2 est passé aux algos de diffusion, mais (si je comprends bien) sans le trick de faire la diffusion dans un espace latent obtenu par VAE.
D’ailleurs Stable Diffusion comme DALL·E 2 utilisent tous les deux le modèle CLIP d’OpenAi pour réaliser l’embedding dont je parlais dans la vidéo.
Débruitage et UNet
Je n’ai pas précisé dans ma vidéo quelle type d’architecture de réseau on utilise pour réaliser le débruitage. Vous savez peut-être qu’en computer vision on utilise les fameux réseaux de convolution, notamment popularisés par Yann LeCun. Mais pour réaliser ça, on a un réseau qui prend plein de pixels en entrée et donne en sortie une quantité limitée de nombres (par exemple la probabilité estimée pour chacune des 1000 classes prédéfinies). Les filtres de convolution permettent notamment de synthétiser les informations spatiales afin d’en extraire des informations sémantiques.
Pour faire du débruitage, on prend en entrée une image, et on doit avoir en sortie une image de la même résolution. Pour cela, on utilise une architecture qui a notamment été inventée pour les questions de traitement et segmentation des images médicales : l’architecture « U-Net ».
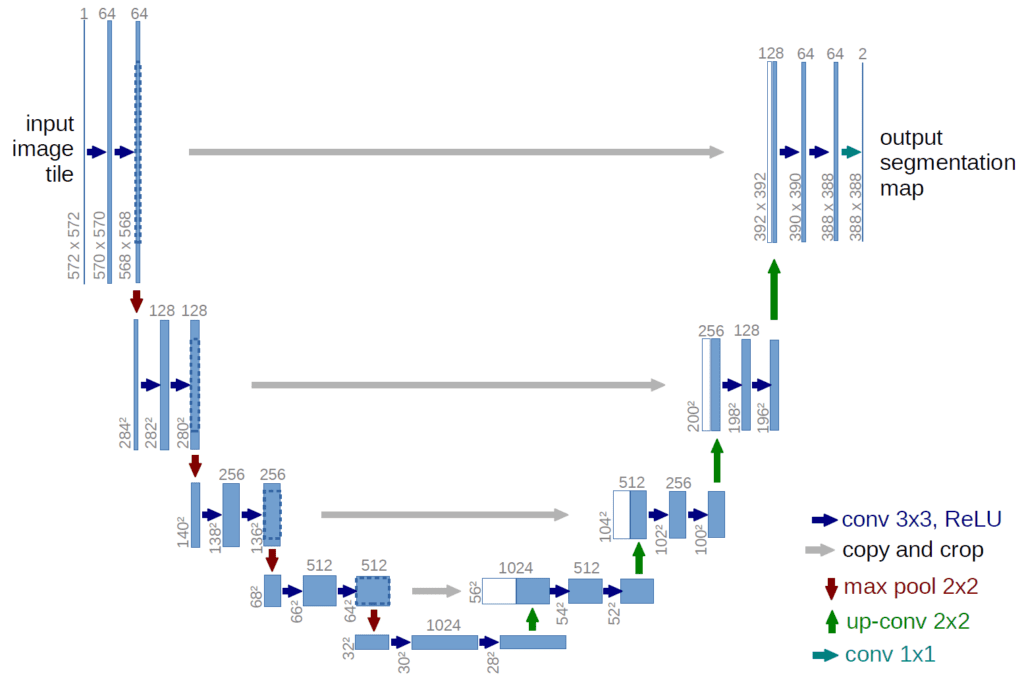 L’idée est de commencer classiquement par enchainer des filtres de convolution et de pooling pour réduire la dimension en augmentant le nombre de canaux, puis de refaire ensuite le chemin dans l’autre sens pour remonter à une image de même dimensions initiales. La subtilité étant que dans cette étape de remontée, on fournit au réseau les étapes intermédiaires qu’on avait dans la descente (ce sont les flèches grises horizontales qui représentent ça sur le schéma).
L’idée est de commencer classiquement par enchainer des filtres de convolution et de pooling pour réduire la dimension en augmentant le nombre de canaux, puis de refaire ensuite le chemin dans l’autre sens pour remonter à une image de même dimensions initiales. La subtilité étant que dans cette étape de remontée, on fournit au réseau les étapes intermédiaires qu’on avait dans la descente (ce sont les flèches grises horizontales qui représentent ça sur le schéma).
Samplers et scheduling
Si vous avez un peu joué avec Stable Diffusion ou certaines des API qui sont proposées, vous aurez noté que les algorithmes proposent plusieurs samplers/scheduler. Il s’agit de différente manière de réaliser le débruitage à partir d’un même réseau de débruitage. Notamment on peut décider du rythme de débruitage. Dans la vidéo j’ai fait comme si on retirait 5% de bruit à chaque fois pour faire le débruitage en 20 étapes. Mais d’une part on peut choisir le nombre d’étapes, d’autre part on est pas obligé d’adopter un rythme linéaire. Donc le « scheduling » du débruitage peut varier, et apparemment certains fonctionnent mieux que d’autres, que ce soit en qualité ou en rapidité.
Inpainting, super-resolution
Parmis les usages possibles des modèles de diffusion entrainés, il y a la possibilité de faire de l’inpainting, donc de laisser l’algorithme remplir certaines parties de l’image, par exemple après avoir effacé quelque chose

ou encore de fournir une sorte d’esquisse et de demander à l’algorithme de la remplir, ci-desous un exemple pour de la génération de paysages.

Dans les deux cas, cela fonctionne toujours selon le principe du débruitage avec conditionnement. On part d’un bruit, et on va le débruiter on conditionnant avec une image qui sert de référence.
A noter qu’on peut aussi utiliser les modèles de diffusion pour faire de l’interpolation entre deux images dans leur représentation « diffusée », qu’on ramène ensuite dans leur représentation d’origine.





8 Comments
Je commentes jamais, mais cette fois fera exception, merci pour ce travail de vulgarisation sur un sujet complexe, qui comporte bien des fantasmes, merci aussi pour la remarque de fin de vidéo sur le droit, qui est un sujet hautement sensible à terme, le tout, dans une présentation accessible.
Le seul point manquant, mais la vidéo était déjà longue et vaste, c’est le risque de voir les IA de mise en avant de contenu, préférer les contenus généré sur ceux produit par les humains ( leur le style, caractéristique ou même volume), ce qui pourrais posé des problèmes sociaux complexe.
Je vous dois un coup, si vous êtes sur IDF, car ce contenu va m’aider.
Bonjour David, super traitement. Questions : en phase d’apprentissage classe-t-on les images par niveau de bruit ou est-il constant ? Combien d’images fournis approximativement ? Ensuite le logiciel fait-il un auto-apprentissage via internet par exemple ? Cordialement
Bonjour,
Je ne pense pas qu’une IA est vraiment intelligente. Par exemple, si on marche dans la rue, nous savons qu’il faut regarder à droite et à gauche avant de traverser, car sinon il y a un risque qu’une voiture nous rentre dedans. Alors qu’une » Intelligence » artificielle le fait parce que c’est écrit dans sont programme.
Je pense que pour le sujet de la fabrication d’images, c’est la même chose : La preuve, l’algorithme ne sait même pas ce qu’il est en train de créer. Une machine, si puissante soit-elle, ne sera toujours qu’une machine qui répond à un programme et qui ne sait même pas ce qu’elle fait. La véritable puissance d’une machine est en réalité seulement déterminée par sa capacité de calcul.
En tout cas, je félicite David pour sa chaîne. Cela fait 12 ans qu’il a un blog qu’il tient régulièrement, et 8 ans si nous prenons en considération Youtube, alors qu’il a un travail familial et professionnel. Je le remercie profondément.
Sincères salutations,
Hassan NEHMÉ
je ne serais pas si définitif. dans ce domaine les surprises arrivent très régulièrement et les mots toujours et jamais sont à proscrire.
exemple avec un papier qui montre que bien que les modèles comme stable-diffusion sont entrainés sur des images 2D sans description de profondeur, les images qui en sortent dès les premières étapes de débruitage contiennent un premier plan, un second plan, un arrière plan, une perspective cohérente, etc… donc il y a une information 3D qu’il a appris à « comprendre » tout seul lors de l’apprentissage.
https://arxiv.org/pdf/2306.05720.pdf
Bonjour,
Tout d’abord, je remercie beaucoup David pour sa chaîne et son blog.
Ensuite, je ne pense pas qu’une IA soit vraiment intelligente. La preuve, la machine ne sait même pas qu’elle crée une image avec un chat ou encore une maison. Une machine ne sait en vérité que calculer à une vitesse supérieure aux humains.
Sincères salutations,
Le scientifique
Merci pour ces très bonnes vidéos, ainsi que ces billets très inspirants qui poursuivent tes sujets, avec les citations majeures. Ce sont des amorces merveilleuses qui nous permettent à notre tour d’halluciner nos propres sujets. J’adore ton usage de ce verbe qui image de façon très anthropocentrique et donc naturelle pour tes followers humains, cette formation numérique d’un contenu à partir d’un bruit. Merci pour tour cela !
Bonjour David,
Grand admirateur de vos vidéos, j’ai besoin de vos lumières sur un point particulier.
Je m’intéresse à l’astrophotographie des objets du ciel profond (galaxies, nébuleuses, etc.).
La mode est maintenant de débruiter les clichés avec des logiciels basés sur l’IA (comme TOPAZdenoiseAI, noiseXterminator, etc.). Les résultats sont absolument spectaculaires.
Sur les forums spécialisés j’ai attiré l’attention sur le fait que les résultats spectaculaires obtenus étaient en fait un leurre. Le sujet est devenu très polémique car mon avis est très contesté.
Je pense en effet que les images obtenues sont enrichies de l’information des images ayant servi à l’apprentissage du logiciel. Autrement dit, on se rapproche sans s’en douter les images de haute qualité des télescopes spatiaux (Hubble ou John Webb). Dans ce cas, les traitements IA me semblent donc « illicites » car rajoutant une information qui n’est pas dans le cliché initial. Les seuls traitements licites me semblent être les lissages, déconvolution ou autres traitements « classiques » n’ajoutant aucune information au signal image.
Peut-être ai-je tort. J’aimerais avoir votre avis sur ce sujet
Avec mes meilleurs sentiments
Pingback: Génération d’images en local avec ComfyUI – Visualisations & décryptages