La nouvelle est tombée il y a déjà plus de deux semaines, je m’attaque enfin à la suprématie quantique de Google !
Alors que puis-je dire pour compléter cette exposé ?
D’une part les « pros » de la mécanique quantique se seront probablement étranglés devant ma notation des états superposés. Je fais comme si les coefficients devant chaque état propre étaient des pourcentages, ce n’est pas le cas, il s’agit en réalité de coefficients complexes, et ce qui compte c’est le module carré. Mais bon, ceux qui le savaient déjà le savaient déjà. Les autres n’en auront probablement jamais l’usage. Ou alors ils auront droit à un « vrai » cours de mécanique quantique !
Pareil pour mon désormais habituel « à la fois » pour le principe de superposition. J’ai déjà fait une vidéo spécifique sur le sujet !
Concernant les portes quantiques, j’ai dit qu’il y en avait « beaucoup », en fait il y en a une infinité ! Mais disons que si on se limite aux portes usuelles, il y en a vite une bonne série à mémoriser. Petit détail amusant : contrairement aux portes classiques, les portes logiques quantiques sont réversibles ! On peut toujours revenir en arrière. Alors que si je vous dit que le bit de sortie d’une porte ET est 0, ça ne vous dit pas d’où on partait exactement.
Tiens d’ailleurs j’ai dit qu’on pouvait appliquer un circuit « de son choix », ce qui faisait de Sycamore un vrai processeur programmable. Techniquement chaque qbit n’est pas directement connecté avec tous les autres. Il y a une sorte de disposition des qbits et des coupleurs, qui font qu’il y a une notion de voisinage.

Les fins calculateurs auront peut-être remarqué un truc bizarre sur l’échantillonnage fait par Sycamore. On prend typiquement \(10^6\) échantillons alors que l’espace des états est de taille \(10^{16}\) ! Eh bien oui, en fait on est très loin d’avoir ne serait-ce qu’un échantillon par état propre, et donc l' »histogramme » est surtout plein de 0, avec des 1 de temps en temps.
Mais ce type d’échantillon suffit pour calculer ce que les chercheurs de Google ont utilisé comme mesure de la fidélité de leur processeur : la cross-entropy qui représente en gros la probabilité qu’aucune erreur ne soit survenue lors de l’application d’un circuit. Sur les graphiques publiés, on voit que pour les cas les plus extrêmes, les valeurs sont quand même très faibles (moins d’1% !)
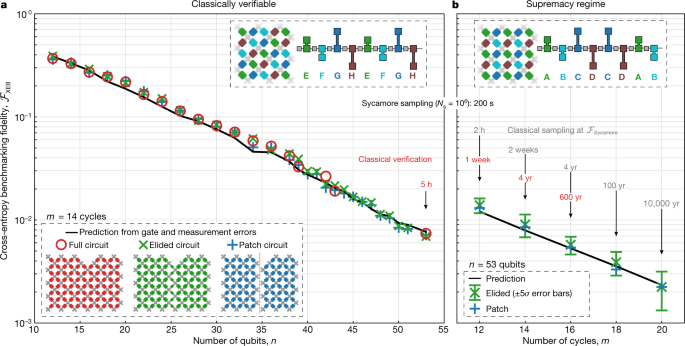
Ce qui signifie que dans ces régimes (et donc celui de la suprématie), le processeur passe son temps à faire des erreurs, et le résultat de la mesure est donc souvent une chaine random.
Tiens au passage signalons que toutes les chaines produites par Sycamore ont été stockées et sont disponibles, donc de futurs calculs classiques seront en mesure d’invalider le cas échéant le résultat.
J’ai été évasif sur la notion de circuit « simplifiable », il faut dire que sur ce coup je fais confiance à ce qui est écrit dans l’article. En gros un cycle consiste en l’application d’un groupe de 8 portes, et si on les choisit selon un schéma donné (par exemple ABCDABCD) il en résulte un circuit « difficile » alors qu’avec un autre schéma (EFGHGHEF) le calcul classique s’en trouve grandement facilité (circuits « patch » dans leur nomenclature)
Sur le calcul de la RAM nécessaire à stocker l’état de Sycamore, 10^16 coefficients (qui sont complexes je le rappelle !) demande disons deux fois 32 bits si on code avec des float, donc 640 millions de Go. Après on doit pouvoir gagner en faisant module et phase. IBM a une estimation un peu moins gourmande puisqu’ils annoncent 128 millions de Go pour 54 qbits. Mais je n’ai pas creusé pour comprendre la différence, on est dans le même ordre de grandeur.
Enfin sur l’estimation du nombre de qbits nécessaires pour faire du Shor en suprématie quantique, c’est tiré de l’article que je cite dans la vidéo. Une notion importante (que je n’ai pas voulu introduire) est celle de qbit « logique » vs qbit « physique ». Un qbit logique c’est en supposant que tout marche sans erreur. Et en pratique on « réalise » un qbit logique à partir d’un certain nombre de qbits physiques, le tout sous la supervision d’un code correcteur. Dans le cas dont je parle et qui est discuté dans le papier, il faudrait donc 500 000 qbits physique pour réaliser un seul qbit logique suffisamment robuste.
Si vous voulez aller plus loin :
La papier de Google dans Nature, en accès libre, et notamment les 60 et quelques pages de « Supplementary Material«
Le blog de Scott Aaronson, qui était notamment « reviewer » de l’article de Google.
Pour la distinction qbit logique et physique et les codes correcteurs : Fowler, A. G., Mariantoni, M., Martinis, J. M., & Cleland, A. N. (2012). Surface codes: Towards practical large-scale quantum computation. Physical Review A, 86(3), 032324.




17 Comments
Bonjour David
Merci beaucoup pour la video et l’explication. Tu as effectivement fait une erreur dans ce billet concernant la quantite de RAM.
Pour stocker 2^53 coefficients complexes, il faut 2^53 * 4 * 2 octets, car un float occupe 4 octets (=32 bits). Ce qui fait 72 millions de Go, et non 640 millions.
Non, c’est tout a fait correct. Revois tes calculs, l’ami.
La bise
Ah je vois, je me suis emmêlé les Bytes et les Bits !
Une autre précision : Summit n’a pas 250 PB de RAM, mais bien 250 PB de stockage (sur disques), et environ 10 PB de RAM (en comptant les différents types de RAM).
Source : https://www.olcf.ornl.gov/summit/
En parcourant rapidement le papier d’IBM, ils semblent bien prendre en compte les taux de transfert de et vers le stockage (p15 mais vraiment j’ai lu ça en diagonale).
Ca reste une grosse machine, mais en informatique, les praticiens n’aiment pas trop se planter d’un facteur 25. 😉
Merci d’avoir traité ce sujet, comme toujours de façon intéressante !
Alors qu’effectivement un facteur 25 pour un théoricien, c’est négligeable 🙂
Merci pour la précision !!
Ils prennent bien en compte le temps de transfert de la donnée vers le disque, page 15 de l’article d’IBM.
Ce qui n’est pas sans importance ! Car dans la pratique (et selon les applications) la bande passante de l’IO disque est très contraignante. On parle d’un facteur 10^5 entre la bande passante disque et la bande passante CPU.
Source (et pour plus de précisions sur ces problématiques HPC): https://dav.lbl.gov/archive/Publications/2016/LBNL-1005709.pdf
Merci en tout cas pour cet article éclairant !
Très bonne vidéo, comme toujours c’est super bien expliqué.
Je pense que tu aurais pu parler d’un truc qui aurait eu sa place dans ce thème : le fait que les physiciens ne savent pas si il y a oui ou non une limite infranchissable entre physique classique et physique quantique.
Bon moi je n’ai pas les connaissances, alors je me base sur les conférences d’Alain Aspect qui en parle.
En gros, la question est de savoir si 1) « en isolant suffisamment de particules quantiques, on peut conserver les états quantiques quel que soit le nombre de particules intriquées » ou bien 2) « est ce que à partir d’un certain nombre de particules intriquées, il n’y aucun moyen d’éviter la décohérence quantique et on fini fatalement par perdre les états intriqués quelques soient nos efforts pour isoler le système ».
Ce questionnement est ultra-intéressant, parce que si on dans le deuxième cas de figure, est qu’au bout de quelques milliards de particules intriquées on se retrouve avec un système qui obéit aux lois de la physique classique et pas quantique, ben… l’algorithmique quantique c’est un peu mort pour les problèmes complexes qui nous intéressent…
Si j’ai bien comprit ce qu’à dit Aspect, bon ben il n’y a plus qu’à intriquer de plus en plus de particules et voir si une limite infranchissable se dessine ou non.
As un ou des liens vers des conférences de ce MR, je suis au travail là (pause déjeuner tardive), et YT est évidemment filtré par le proxy …
Si vous voulez vous essayer à l’informatique quantique et tout ses états, je conseil « The Quantum Game »
2 puissance 53 est 10 millions de milliards (en fait 9) et non dix mille milliards. Erreur à l’oral mais ok à l’écrit sur la vidéo.
L’incertitude en physique quantique ne se trouve pas dans l’état des particules ou de l’énergie, elle se trouve chez les physiciens et les mathématiciens qui ne sont pas certains du tout de comprendre exactement de ce dont il s’agit dans l’ensemble. Vraiment pour ne pas s’en rendre compte il faut ne pas avoir envie de le voir… Ou avoir envie de rêver.
Ca y est j’ai compris.. pfiou… C’est tellement vulgarisé l’informatique quantique que ça en devient faux certaine explication. Je me suis fait avoir par ça.. Bon ya que les cons qui n’admettent pas qu’il ont eu tort… Donc mé culpa… (Moi je passe mon temps à me tromper j’ai l’impression.. mais c’est ça la science j’ai l’impression. Surtout la recherche)
Cela dit j’ai une nouvelle intuition maintenant que j’ai compris : je suis certain qu’on peut simuler l’état probabiliste de chaque QBit, même intriqué, sur une machine classique ! Et de faire tourner ces algorithmes quantiques sur n’importe quel ordi classique jusqu’au bon vieil Amiga ! (avec un nombre potentiellement illimité de QBit !) Je vous parie que je met moins d’un an à trouver !(j’allais dire moins d’un mois mais la preuve que j’apprends de mes erreurs 😀 du calme 😉 )
Bonjour David, je vois bien la difficulté de décomposer des grands nombres mais je n’ai pas compris en quoi le plus grand nombre décomposable par un super ordinateur serait « 4 088 459 ».
Il est assez facile de contourner le problème avec une bête boucle qui teste la division par tous les nombres en commençant par 2 et qui réalise l’opération si le résultat est un nombre entier. J’ai fait un petit script et ça marche très bien. On se heurte bien entendu tout de même à une limite : dans mon cas le PHP me bloque au milliard de milliards (18 chiffres) et mon serveur à une sécurité qui bloque les scripts qui mettent plus de 30 secondes (ce qui permet tout de même de tester les divisions jusqu’à 300 millions).
Peut-être que la difficulté est dans l’usage de l’algorithme de Shor ? J’ai jeté un oeil sur Wikipedia et j’ai rien compris !
Après, c’est vrai qu’on obtient des trucs rigolos. Par exemple 11111111111 = 21649 x 513239. Je mets quand même le lien vers ma page pour ceux qui voudraient s’amuser à décomposer des nombres : https://www.international-football.net/nombres-premiers
Pingback: Google的量子至上性-惊人的科学 - 翻墙网络
Pingback: La Suprématie Quantique de Google — Science étonnante #63 – MovieCS
Pingback: to the origins of a hybrid creature – France News
Pingback: aux origines d’une créature hybride - LBE News