 Le livre Moby Dick, publié par Hermann Melville en 1851, ne connut semble-t-il qu’un succès modeste lors de sa première parution. Ce n’est qu’après la Première Guerre mondiale – et plus de 20 ans après la mort de Melville – que le livre fut finalement acclamé par le public et la critique.
Le livre Moby Dick, publié par Hermann Melville en 1851, ne connut semble-t-il qu’un succès modeste lors de sa première parution. Ce n’est qu’après la Première Guerre mondiale – et plus de 20 ans après la mort de Melville – que le livre fut finalement acclamé par le public et la critique.
Moby Dick fait partie aujourd’hui des œuvres majeures de la littérature anglo-saxonne, et est considéré comme un livre unique, à la langue et au style bien particulier. L’alliance de la numérisation massive des livres et des techniques d’analyse de données permet aujourd’hui de comprendre pourquoi.
La densité de vocabulaire
C’est une évidence, tous les livres ne contiennent pas la même quantité de vocabulaire : on se doute bien qu’il y a plus de mots différents dans Les Misérables et que dans Tchoupi va sur le pot. Et pourtant jusqu’à une époque récente, il était assez difficile de quantifier précisément la richesse de vocabulaire d’une oeuvre. Aujourd’hui, rien de plus simple avec la numérisation des livres !
C’est ce qu’a voulu calculer le chercheur/artiste Zack Booth Simpson. Pour cela il s’est servi des livres numérisés du Projet Gutenberg et a compté pour chacun d’eux le nombre total de mots, et le nombre de mots différents, c’est-à-dire la taille de son vocabulaire. Parmi les livres faisant partie de l’échantillon (et en excluant les dictionnaires), le plus riche est Histoire de la décadence et de la chute de l’Empire romain, publié par l’historien Edward Gibbon à la fin du XVIIIème siècle, avec 43 113 mots de vocabulaire différents !
Toutefois il y a un biais : le livre de Gibbon comporte 6 volumes et plus d’un million et demi de mots ! Pour avoir une mesure plus pertinente, il faut diviser par le nombre total de mots : on a ainsi une mesure de la densité de vocabulaire. Et là, on trouve que le livre le plus dense est … Moby Dick ! Avec 17 227 mots différents pour un total de 211 763, cela signifie que Melville introduit un nouveau mot quasiment à chaque ligne ! Zack Booth Simpson précise d’ailleurs sur sa page que c’est la lecture de Moby Dick qui lui a donné l’envie de faire cette analyse. Ci-dessous un petit graphique que j’ai fait à partir des données publiées sur sa page.
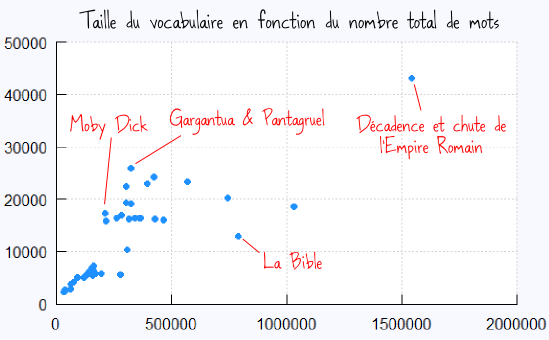
On peut aussi regarder à l’autre bout de l’échelle, et chercher le livre le moins dense, qui s’avère être la Bible : 12 867 mots de vocabulaire pour 790 126 mots au total, soit une densité 5 fois plus faible que Moby Dick.
Une carte de l’univers des livres
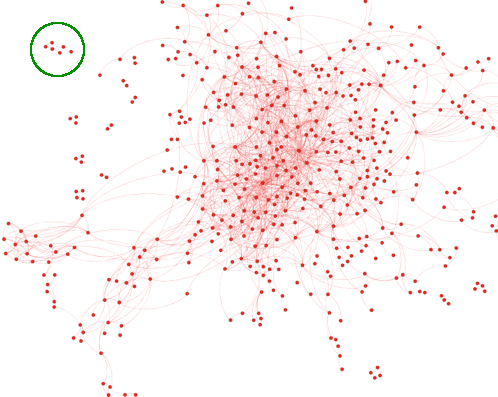 Plus récemment, le linguiste Matthew Jockers a porté l’analyse beaucoup plus loin. En partant d’une base de données de 3600 livres numérisés, il a pour chaque livre calculé près de 500 caractéristiques différentes basées sur le vocabulaire, mais aussi la ponctuation, les thèmes traités, etc. L’ensemble de ces caractéristiques définissent des coordonnées pour les livres, et on peut alors calculer la distance entre 2 livres dans cet immense espace.
Plus récemment, le linguiste Matthew Jockers a porté l’analyse beaucoup plus loin. En partant d’une base de données de 3600 livres numérisés, il a pour chaque livre calculé près de 500 caractéristiques différentes basées sur le vocabulaire, mais aussi la ponctuation, les thèmes traités, etc. L’ensemble de ces caractéristiques définissent des coordonnées pour les livres, et on peut alors calculer la distance entre 2 livres dans cet immense espace.
L’image ci-contre montre une représentation de cette carte des ouvrages, dans laquelle deux points sont d’autant plus proches que les livres se ressemblent. Le petit agrégat isolé dans le coin supérieur gauche représente les œuvres de Melville : des livres qui se ressemblent, mais ne ressemblent à aucun autre !
En utilisant le même jeu de données (qui, précisons-le, ne comporte que des livres du XVIIIe et XIXe), Jockers a montré qu’on pouvait assez facilement deviner si un livre avait été écrit par un homme ou une femme : les livres d’hommes ont tendance a être bien séparés de ceux des femmes sur la carte.
Enfin il a également étudié les relations d’influence (représentées par les lignes sur son diagramme), et conclut que les deux auteurs les plus influents et les plus originaux étaient Walter Scott (qui a écrit entre autres Ivanhoe) et Jane Austen (auteur d’Orgueil et préjugés).
Mots rares et mots fréquents
Pour aller plus loin qu’un simple comptage, quand on analyse le vocabulaire d’un livre, on peut se demander quels sont les mots qui reviennent souvent. Ca n’est pas forcément passionnant car on va trouver inévitablement des mots comme « le », « et » ou « il ». Ce qui est plus intéressant, c’est de se demander ceux qui reviennent anormalement souvent par rapport à leur fréquence habituelle dans le langage. C’est ce qu’a fait Zach Booth Simpson : dans le cas de Moby Dick, il a trouvé que les mots anormalement fréquents étaient whale, harpooneer et sperm (pour ceux qui s’imaginent qu’il y a du porno dans Moby Dick, sachez que « cachalot » se dit « sperm whale » en anglais).
Pour la Bible, les mots anormalement fréquents sont lord, israel, shall, god, moses, jesus, david, offering, tabernacle. Pour le Manifeste du Parti communiste de Marx et Engels, il s’agit de bourgeois, proletariat, communists. Bon, vous allez me dire : rien de bien étonnant dans tout ça !
Ce qui est plus intriguant : les mots anormalement rares. Ce sont des mots qui apparaissent avec une fréquence trop faible dans un livre, par rapport à sa fréquence habituelle dans les autres livres. Pour Moby Dick, on a fortune, happiness, smiled, angry, enemies, pour la Bible girl, boy, school, success, condition, listen, princess, et pour le Manifeste said, love, why, heart, mother, poor, felt. Amusant, non ? La liste plus complète sur la page de Zach Booth Simpson. Son analyse est assez ancienne, je me demande si on peut en faire une version mise à jour avec des oeuvres plus récentes ! En attendant, je pense que je vais abandonner l’idée de lire Moby Dick en version originale…
Pour aller plus loin…
Si vous voulez aller plus loin, commencez par aller voir les sublimes dessins de Paul Lasaine sur Moby Dick. Il raconte sur sa page que Dreamworks a un temps envisagé d’en faire un film d’animation, et qu’il a préparé ces dessins à cette fin. D’habitude je suis peu regardant quand j’ai besoin d’images pour mes billets, mais là c’est trop beau et le respect dû à l’artiste m’interdit un brutal copier/coller.
 Ensuite concernant le travail de Matthew Jockers, j’aimerai bien pouvoir creuser, mais malheureusement c’est pour l’instant impossible : il semble que plutôt que de passer par le processus habituel de publication dans des revues scientifiques, Jockers ait choisi de présenter ses analyses d’abord dans la presse grand public (ici pour NBC) pour annoncer un livre à paraître en 2013 et intitulé Macroanalysis: Digital Methods and Literary History. J’ai tendance à être méfiant avec ce genre de procédé pour faire connaître des travaux scientifiques !
Ensuite concernant le travail de Matthew Jockers, j’aimerai bien pouvoir creuser, mais malheureusement c’est pour l’instant impossible : il semble que plutôt que de passer par le processus habituel de publication dans des revues scientifiques, Jockers ait choisi de présenter ses analyses d’abord dans la presse grand public (ici pour NBC) pour annoncer un livre à paraître en 2013 et intitulé Macroanalysis: Digital Methods and Literary History. J’ai tendance à être méfiant avec ce genre de procédé pour faire connaître des travaux scientifiques !
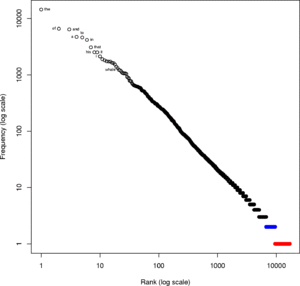
Enfin pour ceux qui se poseraient la question, oui Moby Dick suit bien la loi de Zipf ! (ci-contre). Quant à la loi qui relie la taille du vocabulaire à la taille totale du texte, elle est connue empiriquement sous le nom de loi de Heaps, et s’exprime comme \(V = k n^{\beta}\) où V est la taille du vocabulaire, n la taille du texte, k est un coefficient qui vaut typiquement entre 10 et 100, et l’exposant \(\beta\) est proche de 1/2.
Pour les vraiment motivés : analyse de données linguistiques avec R.
La page de Zach Booth Simpson est assez étonnante : il s’agit d’un programmeur de jeux vidéos, passé à l’art et à la science. Un des rares cas de gens qui finissent par publier dans les revues scientifiques en arrivant de l’extérieur du sérail !


Comments
Pingback: Pourquoi Moby Dick est un livre exceptionnel (et autres enseignements de la littérature numérique…) | C@fé des Sciences | Scoop.it
Passionnant! Décidément l’analyse quantitative de la littérature est un sujet fécond…
C’est bien joli tout ça mais en tant que lecteur, je m’interroge sur la valeur des ces études ainsi que sur leur portée scientifique…
En tant que lecteur, je pense qu’on s’en fout 🙂
Ce que je veux dire, c’est que cette analyse est intéressante mais qu’en aucun cas il ne faut en conclure que tel livre est « meilleur » que tel autre. De même qu’il y a des chansons que j’adore qui n’ont que 3 accords…
Pingback: Pourquoi Moby Dick est un livre exceptionnel (et autres enseignements de la littérature numérique...) | veille numérique et bibliothèques | Scoop.it
Pingback: Gens passionnants | Pearltrees
Le lien de l’analyse de données linguistiques avec R en toute fin de l’article est mort.
Pouvez-vous remédier à ce problème ? Merci !
Tiens c’est marrant, il l’affiche correctement dans mon editeur WordPress, mais pas sur le billet final !
Voici le lien : http://www.ualberta.ca/~baayen/publications/baayenCUPstats.pdf
Ici, le lien n’est toujours pas bon !
Et merci pour cet article !
Pingback: Pourquoi Moby Dick est un livre exceptionnel (et autres enseignements de la littérature numérique...) | Veille pour rire ou sourire | Scoop.it
Si ce n’est pas indiscret, comment tu as fait le premier graphique ? J’aime bien son style ‘handwritten’ sans l’etre vraiment. J’imagine du Python derriere, non ?
Eh eh, me voici obligé de révéler mes petits secrets 🙂
En fait c’est fait avec R (avec pas mal d’options customisées), et ensuite j’édite en Inkscape.
Pingback: Pourquoi Moby Dick est un livre exceptionnel (et autres enseignements de la littérature numérique...) | Actualités sur le livre numérique (Bibliothèques de Trois-Rivières) | Scoop.it
Pingback: Analyse de corpus « L'Endormitoire
Voila un article bien amusant et je vous en remercie, même si les analyse me paraissent un peu trop simpliste.
Je me souviens en particulier que ce genre d’analyse avaient fait dire à des scientifiques que certaines pièces de Molière avaient été écrite par Racine (ou peut être était ce Corneille). A-t-on put conforter cette hypothèse ou n’était-ce que le fait du simplisme du modèle?
Moi qui suis un fan de l’animateur / historien Franck Ferrand, j’ai longuement entendu parler de la « controverse » Molière/Corneille !
Par contre je ne sais pas si elle a été analysée sous l’angle scientifique. En théorie c’est faisable, puisque les méthodes développées notamment par Matthew Jockers permettent de faire de l’analyse de « paternité » des textes. Il a publié sur le sujet
http://llc.oxfordjournals.org/content/early/2012/10/26/llc.fqs041.abstract?keytype=ref&%253Cbr%2520%2F%253Eijkey=HLKipDRkcWd3Yzu
http://www.youtube.com/watch?list=FLhNW_TJE-CmtIVbfaNWuswA&feature=player_detailpage&v=mixWoSidFGc
Bonsoir à tous,
je ne comprends ce qu’il s’est passé, ce sont mes vidéos favorites que je ne parviens pas à rendre publiques d’ailleurs…
Vous avez l’introduction du bouquin dont il est question(MD) à la fin de la liste, lue dans sa langue d’origine.
Un concept que je trouve bien intéressant…
Je vous souhaite une bonne écoute.
Pingback: Moby Dick, un libro extraordinario | Cuaderno de Cultura Científica
Pingback: Pourquoi Moby Dick est un livre exceptionnel (e...
exceptionnel
Pingback: Moby Dick, un libro extraordinario | Matemoción | Cuaderno de Cultura Científica
Pingback: Pourquoi Moby Dick est un livre exceptionnel (e...
a lire aussi sur le meme sujet … Apres les attentats de Paris du 13 novembre 1.2 le Parti Libertarien de France annonce ses mesures anti-terroristes http://www.parti-libertarien.com/actu/attentats-paris-hypocrisie-gouvernement
J’adore Moby Dick. Mais je me demande quel serait le résultat si Simpson avait analysé des texte type directives CEE par exemple. A mon avis, il y a presque un mot nouveau … à chaque mot. Pourtant littérairement c’est nul … lol !
Mais c’est intéressant. Et de voir que les oeuvres de Melville se ressemblent en partie grâce à cette caractéristique: la richesse du vocabulaire. Cela fait donc partie de son « style ».
Pour aller plus loin, il serait intéressant de voir comment les traducteurs prennent en compte cette caractéristique: l’oeuvre traduite est-elle aussi riche que l’original ? Personnellement, je suis incapable de lire Moby Dick dans une autre traduction que celle de Giono. Toutes les autres me paraissent insipides mais je ne sais pas pourquoi.
Et dans un même ordre d’idée, analyser la richesse du vocabulaire des séries télé et de leur traduction. Je suis lassée des séries américaines que mon fils regarde non à cause de leur sujet mais du fait que les personnages disent « désolé » tous les 5 mots. Or un français ne fait jamais ça. Un coup il dit « désolé » mais le coup d’après c’est « je regrette » et puis « Tu ne vas pas être content mais … » etc …
Et pour finir, y a t-il un lien entre la richesse du vocabulaire écrit et celle du langage oral d’une société donnée ?
Pingback: Moby Dick, un libro extraordinario |
Pingback: Moby Dick, un libro extraordinario – Título del sitio