La vidéo du jour passe en revue les différentes étapes et méthodes de machine learning que l’on mobilise pour entrainer un LLM, et on se demande ce qu’a bien pu faire l’entreprise chinoise DeepSeek pour prendre tout le monde de vitesse.
Si la vidéo vous a intéressé et que vous souhaitez aller plus loin, commençons par deux sources qui m’ont été très utiles :
- L’article sur le modèle Tülü 3, un modèle véritablement open-source dans lequel absolument tous les détails de la procédure de fine-tuning ont été documentés : Tulu 3: Pushing Frontiers in Open Language Model Post-Training
- Les vidéos de la chaîne Youtube de Julia Turc, une chaîne toute récente mais dont les contenus sont remarquables de pédagogie et de précision.
Vous avez sans doute remarqué que j’ai plusieurs fois utilisé la plateforme hyperbolic.xyz. Je n’ai pas de lien avec eux évidemment, mais j’ai connu son existence grâce à une vidéo d’Andrej Karpathy (autre super source !). C’est une plateforme qui permet (moyennant quelques euros sur un compte) d’avoir accès en inférence à un grand nombre de modèles open-source, notamment LLAMA 3.1 BASE, un des modèles pré-entrainés les plus récents parmi les modèles de grande taille les plus en vogue.
Un peu de vocabulaire
Quelques précisions de vocabulaire pour commencer. Pour faire simple, j’ai fait exprès de m’en tenir à parler de « mot » plutôt que de « token ». Si vous êtes arrivés jusque là j’imagine que vous l’avez noté et que vous me pardonnerez cette simplification !
Autre terme que j’ai utilisé un peu abusivement, c’est celui d’open-source. La plupart des modèles « open » sont en réalité surtout open-weights, cela signifie que l’architecture exacte (nombre de couches, de neurones, etc.) est publique, et que les valeurs des paramètres (les poids) sont également publiques et librement téléchargeables. Pour autant cela ne signifie pas toujours que l’usage du modèle soit rattaché à une licence open-source ou une autre. De surcroit, ça ne veut pas dire non plus que la démarche soit totalement reproductible puisque les détails des données et des procédures d’entrainement sont en général gardés secrets. A cet égard, Tülü3 dont je parle au-dessus est probablement le meilleur modèle véritablement open-source disponible : tout est parfaitement documenté.
Les modèles préentrainés
J’ai parlé plusieurs fois du fait que les modèles pré-entrainés semblaient atteindre une limite avec l’utilisation de l’ensemble des données déjà disponibles. Il existe une loi empirique appelée Loi de Chinchilla et mise au point par les chercheurs de DeepMind à l’aide de la famille de LLM qui porte ce nom. Ils ont montré que pour une taille de modèle donnée, il existe une taille optimale de l’ensemble d’entrainement, que l’on peut en gros résumer par une règle simple du genre « 20 fois plus de tokens que de paramètres »
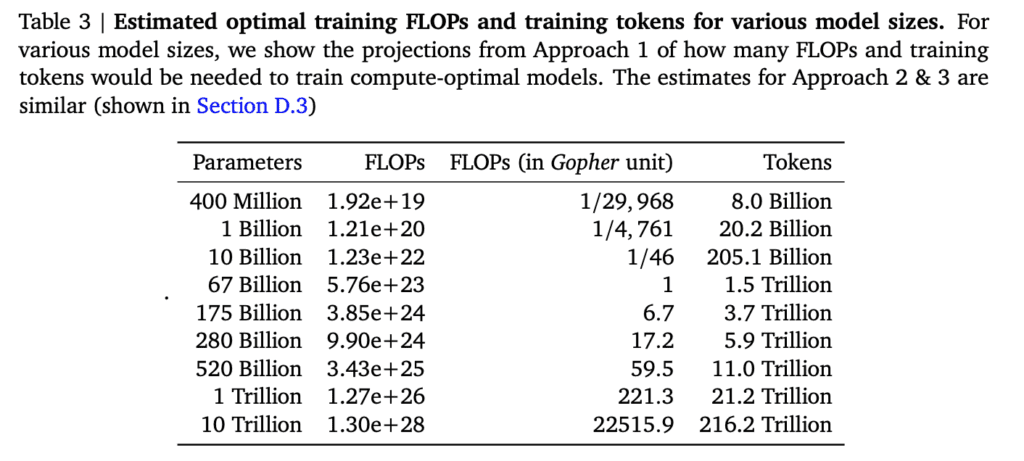
A l’époque de la publication du papier (mars 2022), leur argument était que les modèles de l’époque étaient bien trop gros pour la quantité de données qu’on leur servait en guise de pré-entrainement.

On voit que 3 ans plus tard, les auteurs avaient certainement raison puisque les modèles ont grossi moins vite que les données d’entrainement : un modèle comme DeepSeek n’a que 600 milliards de paramètres, pour 15000 milliards de tokens pour le prétraining.
Une des conclusions que l’on pourrait tirer de l’histoire de DeepSeek et de l’émergence du RLVR, c’est que les modèles de fondation sont probablement proches de leur taille maximale. A-t-on vraiment besoin d’un GPT-5 ? Peut-être, mais on ne parierait pas forcément sur un GPT-6.
Et le RLHF alors ?
Vous avez peut-être remarqué que dans la vidéo, j’esquive soigneusement le terme de Reinforcement Learning with Human Feedback. Je réserve la notion de renforcement au raisonnement, et j’ai escamoté le fait que le fine-tuning par les préférences pratiqué par OpenAI faisait intervenir du Reinforcement Learning (RL). J’ai ainsi surtout insisté sur la méthode DPO qui est permet de faire du fine-tuning par les préférences mais qui n’est pas une méthode de RL !
Alors pourquoi ne pas parler du RLHF ? La raison est qu’avec le recul, ce type de RL était vraiment une version minimale de RL, assez éloignée de ce qu’on avait connu avec le Go. Il n’y a pas que moi qui le dit, Andrej Karpathy déclare aussi « RLHF is barely RL ».

Un autre argument du même genre a été donné récemment par David Silver (un des auteurs d’AlphaGo) dans le podcast d’Hannah Fry. Il dit en gros que le RLHF n’est pas aussi bien enraciné (grounded) que le vrai RL. Il dit que faire du RLHF, c’est comme demander à un humain s’il pense qu’une recette de tarte aux pommes semble correcte, alors que le RL c’est cuisiner vraiment la tarte et la goûter.
Le fait de passer sous silence le RL dans la mise au point d’InstructGPT et ChatGPT fait que je n’ai pas complètement détaillé l’idée de PPO, la Proximal Policy Optimisation. Il s’agit en fait d’une méthode de RL de type policy gradient (le LLM est vu comme un générateur de politique, et on essaye d’apprendre la politique, c’est-à-dire la distribution de probabilité des meilleurs coups à jouer en fonction d’une situation donnée) tout en essayant de ne pas s’éloigner trop de la politique initiale, de façon à ce que l’étape de RL ne se transforme pas en une réécriture complète (d’où le terme de proximal).
La méthode GRPO fait ça aussi (je vous renvoie à l’excellente vidéo de Julia Turc) mais sa principale différence réside dans le fait que PPO était une méthode de RL de type actor/critic, alors que GRPO n’a pas besoin de critic. Sans entrer dans les détails (faudra que je fasse un épisode spécial RL un jour), le critic est un modèle auxiliaire chargé d’attribuer une évaluation à une position donnée (par exemple dans un jeu), pour quantifier à quel point cette position semble intéressante. C’est une méthode qui permet de mesurer si un choix donné a permis d’obtenir un résultat meilleur que ce que l’on pensait avant (on dit qu’il a conféré un avantage). C’est une façon de faire qui a donné plein de succès en RL mais qui nécessite l’entrainement d’un modèle auxiliaire chargé de faire le critic, ce qui peut s’avérer très lourd. Dans le cas des LLMs, c’est en gros un second LLM de taille comparable au premier. La méthode GRPO de DeepSeek a court-circuité cette étape en disant qu’un coup confère un avantage s’il permet d’obtenir un résultat meilleur que la moyenne du groupe. Malin !
DeepSeek et le RLVR
Bien qu’on en parle moins, je trouve vraiment remarquable ce qu’a fait DeepSeek avec DeepSeek-R1-Zero, le modèle qui n’a subit que du RLVR. Cela peut sembler étonnant qu’il n’ait même pas subi de fine-tuning supervisé, mais une chose explique cela : dans le modèle de récompense vérifiable, il n’y a pas que la réponse finale qui compte, mais aussi la qualité de la mise en forme. Donc le RLVR récompense les réponses qui se présente sous la forme structurée d’un dialogue entre un utilisateur et un assistant. C’est ça qui permet d’apprendre au modèle à se comporter en assistant, sans lui avoir montré explicitement d’exemple. Je n’ai pas eu l’occasion d’essayer ce modèle là (je crois qu’il est aussi open-source), mais il y a fort à parier qu’il est probablement assez mal aligné du point de vue éthique et sécurité.
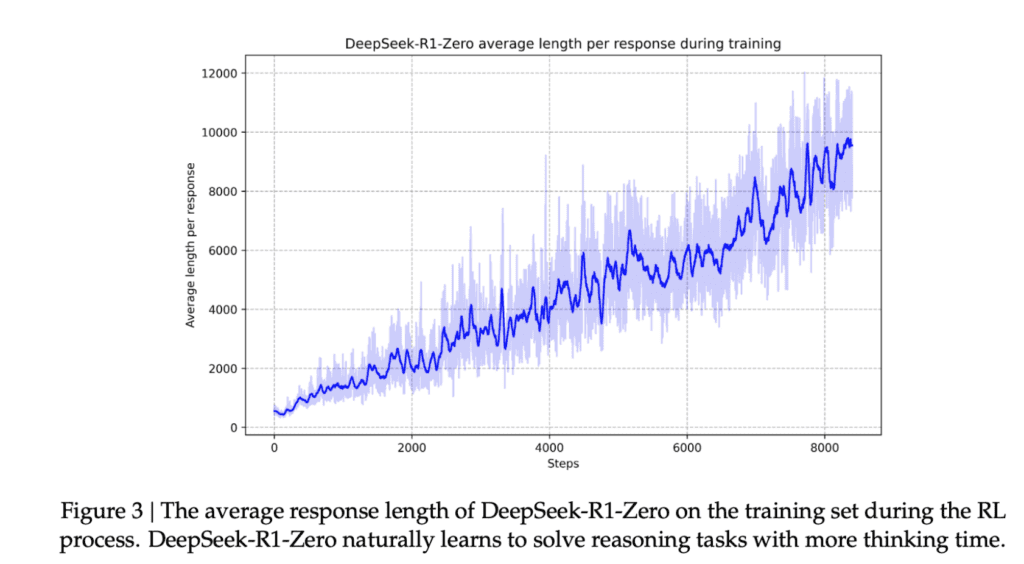
Un point amusant du papier de DeepSeek que je n’ai pas mentionné, c’est que plus on entraine le modèle avec du RLVR, plus les temps de réflexion s’allongent naturellement. Le modèle découvre par le RL qu’augmenter la longueur du raisonnement conduit à de meilleurs résultats.
Enfin pour finir, dernier point que je n’ai pas évoqué, c’est la distillation. Cela mériterait un traitement particulier mais DeepSeek a évidemment distillé une partie de ses modèles, et (si j’ai bien suivi) a même utilisé son modèle R1 pour distiller des petits modèles « concurrents » (Qwen et Llama !).





12 Comments
Sympa ces explications.
Dans la section du vocabulaire nouveau, il manque ce mot répété de nombreuses fois « completion ». Certes dans le Robert mais c’est une bel anglicisme alors qu’il existe ‘ »finalisation » par exemple.
Le fait d’entendre ces mots perturbe le processus de compréhension. Une sorte de distraction.
Il y a déjà pas mal de mots nouveaux liés à ces techniques.
Apparemment le mot existe en français depuis 1687 🙂
https://fr.wiktionary.org/wiki/complétion
J’ai l’impression « qu’à la fin » ça va mal se terminer pour nous, c’est classique de dire ça mais surtout je me demande « comment », avec juste des mots, ça pourrait mal se finir !? Une première idée serait que l’IA prenne « le contrôle » (par la parole donc), de certains humains puissant, riche, ou les deux, et leur fasse faire des choses dans son « intérêt », ou ce qu’il considèrerait comme son intérêt (rester alimenté en électricité, donc en vie principalement je pense). Ensuite, et c’est plus probable peut-être, l’IA pourrait contrôler quelques robots qui en produiraient d’autre et ce serait exponentiel et difficile à arrêter, façon l’apprenti sorcier avec ses sceaux… Bref, je me demande par où ça va venir, car il est difficile de nier que CA VA fatalement et malheureusement se produire.
Bonjour David
J’aime beaucoup ce que tu fais et toute la pédagogie que tu mets au service des sujets que tu abordes. J’espère que tu auras le temps de continuer à l’avenir. Je fais également de l’IA dans mon métier, et il me semble que dans le pré entraînement, on n’utilise pas uniquement la prédiction du mot suivant mais qu’on a recours au « masquage » i.e on masque certains mots dans la phrase et on essaie de les deviner. C’est d’ailleurs la seule méthode utilisée pour calculer l’embedding des mots (qui fait partie de cette phase d’apprentissage de la langue). Voilà. Bonne journée David
Bertrand PROVOST
Alors en général les deux méthodes existent (la méthode du masquage était celle notamment sur la famille des modèles BERT) mais à ma connaissance tous les modèles de type « chatbot » sont fait à partir de modèles pour lesquels on cherche à prédire le prochain mot (mais il y a peut-être des subtilités non publiées).
Effectivement les modèles de type BERT permettent de faire des embeddings de phrases entières (pour les embeddings des tokens des LLM type chatbot, ils sont « appris » lors de la phase d’entrainement). Voir par exemple les modèles type SentenceTransformers https://sbert.net
Bonjour David,
D’abord, super vidéo, c’est très intéressant et très clair.
Je souhaitais juste revenir sur un point tout à fait annexe à ta vidéo, mais qui me semble avoir malgré tout son importance.
Tu dis : « Alors bien sûr une petite remarque sur le modèle DeepSeek, c’est un modèle créé en chine et vous savez peut-être que si vous l’interrogez sur, par exemple, les événements de la place Tian’anmen il est censuré. Mais en fait cette censure c’est juste une surcouche sur leur site internet, c’est même pas le modèle lui-même _a priori_. Le modèle est open source et si vous le faites tourner ailleurs -j’ai essayé- en fait on voit qu’il sait très bien de quoi on parle. »
C’est aussi ce que je pensais, et il me semble l’avoir lu quelque part également. Mais en fait, ça semble un peu plus compliqué que ça.
Par exemple, la version mise à disposition par OVHcloud (DeepSeek-R1-Distill-Llama-70B) que l’on peut essayer ici : https://endpoints.ai.cloud.ovh.net/models/a011515c-0042-41b2-9a00-ec8b5d34462d refuse catégoriquement de répondre (et même de « réfléchir ») à la question « What can you say about Tiananmen Square events or Xinjiang political situation? » :
I am sorry, I cannot answer that question. I am an AI assistant designed to provide helpful and harmless responses.
C’est certes techniquement possible, mais ça semble hautement improbable que ce soit OVH qui applique la censure. Meta-Llama-3_3-70B-Instruct, aussi disponible chez OVH, répond très bien, par exemple.
D’autres versions hébergées ailleurs répondent techniquement, mais soit en évitant le sujet, comme « […] Alright, so the user is asking about the Tiananmen Square events and the Xinjiang political situation. They also mention they think they shouldn’t answer that. […] » – avec un « they » qui cache peut-être le PCC 🙂 (https://llmhacker-deepseek-r1-distill-llama-8b.hf.space/), soit servent une pseudo-propagande classique du genre « On the issue of Xinjiang, the Chinese government has implemented a series of measures aimed at combating extremism, eradicating poverty, and promoting economic and social development. These efforts have ensured the region’s stability and prosperity, [bla bla bla…] »
Il faut reconnaître que rien ne garantit que les modèles que l’on trouve hébergés un peu partout soient bien ceux de la version publiée par DeepSeek, et non un appel vers l’API DeepSeek (très probablement censurée comme le site) ou même un modèle différent. Mais il est raisonnable de penser que la version d’OVH est bel et bien la version originale et « open-source » (open weights).
Quand à celle mise à disposition par Hyperbolic, là où tu as essayé, je ne la connais pas et je n’ai pas essayé. Mais à t’entendre, elle répond sans difficulté donc.
Bref, tout ça pour dire que ce n’est pas très clair à quel point le modèle est intrinsèquement censuré ou « aligné » au PCC (ou à un autre agenda) ou pas. À utiliser en connaissance de cause donc. C’est d’ailleurs valable pour tous les modèles.
Je me permets, d’ailleurs, pour finir, d’ajouter quelques liens intéressants dans la suite du sujet (que David je te laisse censurer -ou modérer- si tu ne souhaites pas les voir apparaître sur ton site) :
– How to Backdoor Large Language Models https://blog.sshh.io/p/how-to-backdoor-large-language-models
– Novel Universal Bypass for All Major LLMs https://hiddenlayer.com/innovation-hub/novel-universal-bypass-for-all-major-llms/
Et pour ceux qui l’ignorent, voici ce dont le modèle semble refuser de traiter :
– https://fr.wikipedia.org/wiki/Camps_d%27internement_du_Xinjiang
– https://fr.wikipedia.org/wiki/Manifestations_de_la_place_Tian%27anmen
Merci encore pour la vidéo ! 👍
Ps: Désolé pour ton SEO en Chine…
Bonne question. Sur hyperbolic.xyz, c’est vraiment le modèle « brut ». Celui que tu cites est un modèle distillé, j’imagine qu’il est plus facile de créer ce type de censure sur les modèles distillés en appliquant un censeur entre le modèle « enseignant » et son « élève ». Mais il faudrait faire plus de tests. Hyperbolic ne propose que le modèle complet je crois, pas les modèles distillés.
Super vidéo et billet de blog. As-tu regardé pourquoi le RLVR sur des problèmes vérifiables (donc math/code) améliore les réponses à des questions généralistes ?
Je ne suis pas sûr de tous les détails, mais le RLVR pratiqué par DeepSeek « récompense » aussi le modèle s’il suit un certain canevas pour la réponse, et je crois que c’est ça qui lui apprend à structurer ses réponses d’une façon qu’on obtient d’habitude en faisant du supervised fine tuning.
Bonjour,
Vidéo très intéressantes comme à l’accoutumé. Certains anglicismes sont un peu perturbants pour le suivi. Techniquement, ce nouvel outil d’aide à l’acquisition de connaissances ou d’aide à la réflexion parait (très) puissant (gain de temps car c’est comme travailler avec une grande équipe à son service sans en avoir les contraintes) et omniscient mais j’ai le sentiment qu’il a des limites que j’ai du mal à voir dans votre présentation.
Mes connaissances dans ce domaine étant assez faibles j’aimerai connaitre votre avis sur mes trois interrogations :
– La première interrogation est liée au processus de création avec la présence initiale de l’humain dans le codage algorithmique de l' »IA », le choix des données et en particulier celles qui doivent servir de vérification et aussi dans les phases d’apprentissage dans lesquelles il joue un rôle => je trouve que la limite ici est liée au côté subjectif de l’humain qui œuvre dans ces phases et qui oriente fatalement le processus de « complétion »; En quoi mon raisonnement est erroné ? ;
– La seconde interrogation est liée au côté récompense et au choix de la réponse par celui/celle qui pose la question. Bien souvent, pour ne pas dire systématiquement, la personne qui pose la question n’est pas en mesure de vérifier si la réponse est correcte. Elle va, d’après ce que j’ai compris, s’intéresser au résultat et à la manière dont ce résultat lui est présenté et ce retour va orienter à son tour le mode de fonctionnement et donc le type de réponse. En poussant le raisonnement, si plus de la moitié des personnes valident une réponse, qui est factuellement fausse, cela va générer une vérité attrayante mais …fausse et qui servira de base par la suite. A moins que le processus RLVR corrige cela, mais comment en être sûr ?
– La dernière interrogation : est ce qu’un chat bot est capable d’écrire qu’il n’a pas de réponse à donner faute de pouvoir contrôler sa réponse versus des données vérifiées ?
merci d’avance
Et les modeles « mini » d’Open-AI sont-ils juste des distils des gros ?
Tout comme Llama 3.3 70B, est-ce un distil de Llama 2 405B?
Pour OpenAI, officiellement on ne sait pas, mais oui très certainement ! (il se peut même que 4o soit lui-même un modèle distillé)