En ces temps troublés, j’ai eu bien du mal à trouver un sujet à traiter qui me motive, et qui nous sorte des réflexions sur le COVID-19. Le salut est finalement venu d’un sujet un peu en dehors de ma zone habituelle…et qui n’est pas sans résonance avec l’actualité !
Tout d’abord, je voudrais remercier celui par qui ce sujet est arrivé à mes neurones : Cyrille Rossant dont l’excellent livre sur le calcul interactif en Python mentionnait l’article de Reinhart et Rogoff comme une bonne raison de s’intéresser de près à la reproductibilité des expériences numériques.
Je crois que j’en avais déjà entendu parler (probablement dans cette tribune), mais l’histoire était sortie de ma mémoire…
Une sombre histoire de moyenne
Il y a un point technique important que j’évoque dans la vidéo, sans le détailler : la manière « bizarre » de faire les moyennes, utilisée par R&R dans leur papier. Voici le détail.
Dans la base, on a environ 1200 lignes : chaque ligne correspond à un couple Année-Pays. Intuitivement, si l’on veut réaliser une moyenne, on va moyenner sur chaque année-pays, de façon à ce que chaque ligne de donnée ait un poids identique dans le résultat final.
Mais ce qu’on fait R&R, c’est d’abord de grouper en 4 catégories de dette par pays, puis de moyenner. On le voit bien sur la capture d’écran que je montre dans la vidéo :
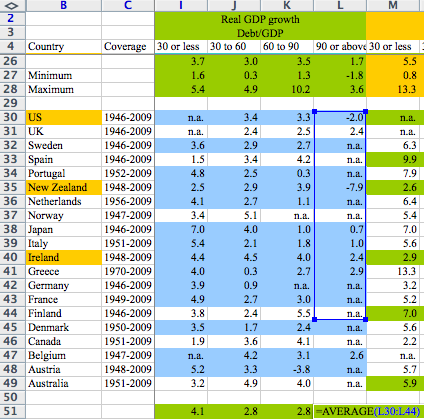
Cela peut paraitre assez intuitif de faire comme ça, mais cela cache une faille. Sur les chiffres que l’on voit, le 2.4% de UK dans la tranche « >90% » est une moyenne obtenue sur 19 lignes de données (toutes les années entre 1946 et 1964, où le Royaume-Uni a été au-dessus de 90% de dette). En revanche, le -7.9% de la Nouvelle-Zélande correspond à … une seule année : l’année 1951.
A la fin, les deux auront le même poids dans la moyenne qui donnera le fameux -0.1% qui s’est révélé faux. Si on ajoute à cela l’oubli de certaines données et de certains pays dans la moyenne, on voit que le fameux résultat est dû uniquement à cela : l’année 1951 en Nouvelle-Zélande. Si on enlève juste ce point, le -0.1% devient un +1,2%.
Bref, le résultat clé de R&R, c’est juste dû à l’année 1951 en Nouvelle-Zélande et ses -7.6% de (dé)croissance. Ah oui petit détail savoureux : en plus des 3 erreurs mentionnées dans la vidéo, il y avait aussi une 4e erreur « de transcription » qui fait que le vrai chiffre de -7.6% pour la NZ avait été mal recopié en -7.9%.
Edit du 20/04 : Comme beaucoup l’ont remarqué, il y a aussi le caractère totalement arbitraire du fait de segmenter la dette en 4 tranches 0/30/60/90%. De ce que j’en sais, c’est effectivement considéré comme une mauvaise pratique en statistiques de prendre une variable continue, et de la discrétiser de la sorte : on perd en information et on gagne en arbitraire.
Que celui qui n’a jamais fait d’erreur Excel leur jette la première pierre…
J’espère que le ton de la vidéo fait correctement ressortir le message principal, qui n’est pas de se moquer d’une boulette Excel par des pontes de Harvard, mais surtout de mettre en valeur les structures existantes pour éviter que ces erreurs (humaines, et normales) aient des conséquences :
La revue par les pairs : dont je ne comprends pas toujours pourquoi elle ne s’est pas appliquée dans ce cas là. Apparemment c’était un numéro de la revue regroupant des actes de conférence. Mais pourquoi pas de peer-review ? Et comment un article peut-il alors se prévaloir du prestige de la revue ?
Edit du 20/04 : Suite à plusieurs conversations avec des économistes professionnels, j’ai un peu éclairci cette situation. Avant 2018, le numéro du mois de Mai de l’American Economic Review (AER) était consacré aux proceedings de la conférence de l’American Economic Association. Pour les économistes, il était semble-t-il bien connu que ce numéro de Mai était spécial et différent, sans peer-review formel, avec des papiers plus courts, etc. Donc les « pros » savaient faire la différence en voyant que « c’était dans le numéro du mois de Mai ». Toutefois dès qu’on est un peu extérieur au domaine, si on n’a pas cette connaissance, on ne peut pas deviner qu’une publication « dans le numéro de Mai » n’a pas la même valeur qu’une publication dans les autres numéros de l’AER. Depuis 2018, les choses ont été clarifiées car l’éditeur a décidé de transformer ce numéro spécial en une édition à part entière, avec un vrai nom différent « AEA Papers&Proceedings ». Mais en 2010, quand le R&R a été publié, cette distinction n’avait pas encore été faite.
Le partage des données et des codes : il faut reconnaitre que R&R ont quand même eu l’honnêteté intellectuelle de partager leurs données. On n’aurait pas forcément parié dessus, d’autant que la demande émanait de ce qui semble être un « petit » département d’économie voisin. A la fin de cette histoire, c’est quand même David qui a ridiculisé Goliath !
Par ailleurs, sur ce fil Twitter : quelques compléments sérieux d’un macro-économiste sur ce que l’on comprend des liens entre dette et croissance.
Quelle influence réelle ?
C’est probablement mission impossible d’essayer de savoir quelle influence réelle a exercé cet article sur les décisions politiques prises à l’époque.
Je vous balance en vrac quelques références intéressantes :
https://www.bbc.com/news/magazine-22223190
https://theconversation.com/the-reinhart-rogoff-error-or-how-not-to-excel-at-economics-13646
https://qz.com/75117/how-influential-was-the-study-warning-high-debt-kills-growth/
https://www.newyorker.com/news/john-cassidy/the-reinhart-and-rogoff-controversy-a-summing-up
Une dernière référence, que je n’ai pas osé citer dans la vidéo par manque de source. Il semblerait que Ken Rogoff ait donné une interview au Nouvel Obs en 2010 pour parler de ces travaux. Mais je n’en ai retrouvé trace que sur un blog, pas sur le site du Nouvel Obs. Peut-être l’interview a-t-elle été retirée suite à l’affaire ?
Edit du 20/04 : Fraude ou boulette ?
Dans les commentaires de la vidéo, pas mal de gens estiment qu’il s’agit là d’une fraude évidente de la part de R&R, possiblement motivée par un agenda politique, voire de la corruption (hypothèse assortie parfois d’une dose de théorie du complot…)
C’est évidemment très difficile de juger s’il y a fraude ou pas. L’hypothèse me parait improbable, car dans ce cas ils n’auraient pas fourni leurs données aux chercheurs de Amherst, rien ne les y obligeait.
Si j’avais à parier, je miserai plutôt sur un biais de confirmation. Ces chercheurs avaient peut-être « envie » de trouver un résultat de ce genre, et une fois qu’ils l’ont eu (suite à une/des erreurs), ils n’ont pas cherché plus loin.
Edit du 20/04 : Corrélation / Causalité
Beaucoup dans les commentaires ont aussi noté que je n’insistais pas assez sur le glissement corrélation/causalité. Il faut dire que dans le papier, le discours porte uniquement sur une « association » entre dette et croissances, les chercheurs se gardent bien de parler de causalité.
Pour le dire vite, sur ce point précis, le papier est plutôt « clean ». Mais clairement dans la façon dont ça a été « vendu » ensuite, cela a pu être interprété ou présenté comme une causalité.
Edit du 20/04 : Science reproductible et open ?
Sur Twitter, il y a eu des débats intéressants sur la pertinence ou pas de partager toutes ses données (et les défauts que cela a dans un environnement de recherche compétitif « publish or perish »). Je vous y renvoie !
Et sinon, on m’a signalé que l’INRIA a un MOOC sur la recherche reproductible, qui met notamment en avant l’usage de Notebooks (comme vous m’avez vu le faire dans la vidéo avec JupyterLab)
Le MOOC Recherche reproductible : principes méthodologiques pour une science transparente
Et pour finir, ceux qui voudraient jouer avec le code et mon analyse rudimentaire en Python : https://github.com/scienceetonnante/Reinhart-Rogoff





41 Comments
Salut
«Dans la base, on a environ 1200 lignes : chaque ligne correspond à un couple Année-Pays. Intuitivement, si l’on veut réaliser une moyenne, on va moyenne sur chaque année-pays, de façon à ce que chaque ligne de donnée est un poids identique dans le résultat final.»
Il manque un bout dans ton texte (on va moyenne?). Et il y a une drôle de faute («est un poids» au lieu de «ait un poids»)
D’un admirateur de Québec, Claude
Heureusement qu’il y a la relecture par les pairs…c’est corrigé, merci 🙂
« pour parler de ces travaux » il y a un espace en trop entre « parler » et « de » 😉
Sinon pour le « partage des données et des codes », je soutiens ça à 10 000%, ça devrait être la base pour tout article scientifique !
Sujet très intéressant, et d’autant plus au vu de l’actualité.
J’ai fais ma petite analyse de mon côté, et ce qui est intéressant de voir, c’est qu’en traçant la croissance en fonction de l’année on obtient un R² = 0,12, soit 3 fois plus significatif que celui de la croissance en fonction de la dette.
Voir les graph ici : https://zupimages.net/up/20/16/cx39.jpg
Mais il est tout de même assez édifiant que la conclusion de l’étude concernant ce seuil à 90% aurait pu être trés facilement remis en question par une simple étude visuelle des données brut sous forme de graph.
Ce résultat n’est pas surprenant du tout. La croissance a eu tendance à être constante et assez forte sur le début de la période étudiée par cet article, puis à chuter depuis régulièrement avec les années.
Mais c’est surtout des raisons physiques, comme la production d’énergie, qui ont amené la croissance à diminuer avec les années. Il faudrait être économiste pour conclure de votre analyse que la croissance diminue en fonction de comment on nomme l’année dans laquelle on se trouve.
La même année, le FMI avait publié un document de travail reconnaissant une erreur de calcul du multiplicateur fiscal, ce qui laissait planer le doute sur le bien-fondé de leurs recommandations de politiques d’austérité. Des détails ici : https://www.captaineconomics.fr/-fmi-erreur-calcul-austerite-croissance-olivier-blanchard
Par ailleurs, au-delà de l’erreur de calcul, une des critiques adressées à Reinhart et Rogoff porte sur le passage de la corrélation à la causalité. On peut imaginer qu’une forte dette plombe la croissance (encore que, cela demande à être justifié). Mais la forte croissance peut expliquer la faible dette, par de meilleures capacités de remboursement.
Hello David,
Toujours aussi agréable de te lire, peut être encore plus en ce moment! Ton dernier article sur la propagation d’un virus et les stratégies de gestion d’une pandémie était juste génialement éclairant. Je l’ai beaucoup partagé.
Je t’envoie juste un petit passage de l’article que tu viens de publier parce que j’ai vu que quelques petites fautes avaient échappé à ta relecture, ça n’a aucune importance pour moi mais je me dis que je préfère que tu puisses corriger si tu as envie.
« Dans la base, on a environ 1200 lignes : chaque ligne correspond à un couple Année-Pays. Intuitivement, si l’on veut réaliser une moyenne, on va moyenne sur chaque année-pays, de façon à ce que chaque ligne de donnée est un poids identique dans le résultat final. Mais ce qu’on fait R&R, c’est d’abord de grouper en 4 catégories de dette par pays, puis de moyenner. On le voit bien sur la capture d’écran que je montre dans la vidéo »
J’espère que tout va pour le mieux pour toi en ces temps incertains, et à très bientôt de lire un nouvel article de Science Étonnante.
Bravo encore pour la grande qualité de tes publications, aussi bien sur le plan scientifique, que sur le plan pédagogique et aussi du choix des sujets. C’est tellement agréable de te lire et de t’écouter!
Bien à toi, Michael
Envoyé de mon iPhone
>
excellent article comme d’habitude
la répartition selon 0/30/60/90 est également critiquable, car leur poids relatif est très différent en terme de Qté de données : 426/439/200/110
une répartition selon 0/20/40/60 serait plus équilibrée avec 253/328/284/310, et réduirait encore la baisse de croissance : 4.4 / 3.5 / 3.0 / 2.8
Merci pour la vidéo et le post, toujours au top.
Je ne suis ni économiste ni statisticien mais je me souviens de ta vidéo sur les statistiques et le facteur de confusion et cette étude m’y a beaucoup fait penser. Le taux d’intérêt servi sur la dette d’un pays n’est il pas critique ici? Il aurait été intéressant de comparer le taux de croissance avec la charge de la dette, plutôt que son montant? Je me demande si on ne pourrait pas arriver aux conclusions exactement inverses avec cette approche? Il ne faut pas oublier qu’une dette a 50% du PIB et des taux a 4% coûte le même montant chaque année qu’une dette a 100% avec des taux a 2%… L’exemple extrême etant le Japon qui parvient encore a générer une croissance légèrement positive malgré une dette a plus de 200% du PIB…
Une idée sur les raisons qui s’opposent à l’établissement de la revue ouverte pré et post-publication avec le copyleft sur l’ensemble du ‘matériel’ au sein des institutions publiques de la Recherche ? Et sur un mécanisme pour appuyer là où c’est pertinent ?
Et en cherchant un peu, vous pourrez même constater que les données source n’ont elles-mêmes pas de grande cohérence.
Par exemple, la dette publique française citée n’est pas vraiment compatible avec les données insee, avec des écarts de 10 à 20%.
Pour ce qui est de la croissance du PIB, déjà on ne sait pas trop quel type de croissance du pib il faut regarder (monnaie courante, constante ? En parité de pouvoir d’achat ou pas ? En monnaie locale ou USD ?), et j’ai beau avoir cherché, je n’ai pas trouvé de source données officielle qui donne précisément les chiffres donnés pour la croissance Française. Les chiffres banque mondiale de croissance du PIB en monnaie locale constante semblent corréler quelque peu, mais pas tout à fait bien.
Au passage, ce travail m’a permis de m’apercevoir que les années 1973 à 1978 pour la France manquaient.
La qualité des données de base est donc, même elle, discutable.
Cette affaire est incroyable.
Bonjour mr science étonnante et merci pour très sujets toujours variés et très bien présentés!!
Une question me taraude : que donnerait le nuage de point si on le regardait évoluer dans le temps… Je ne connais pas python mais je crois que tu saurais faire cela facilement…. histoire de voir si le lien mis en évidence aussi léger soit-il existe vraiment en détaillant les données…
Moi ce qui m’a également dérangé, c’est la pertinence des différents encarts choisis (0-30%/30-60%/60-90% et 90% et plus). C’était quelque chose d’habituel dans le milieu ? Pourquoi pas des encarts 0-20, 20-40, 40-60… ? On peut se demander s’ils ont pas sélectionné volontairement ces encarts pour exagérer le plus possible ce qu’ils voulaient obtenir au départ (une baisse significative dés 90%). D’autant plus que l’encart » >90% » est probablement beaucoup trop large par rapport aux autres encarts. Concrètement, cela va jusqu’à combien ? 150% ? 200% ? Car si effectivement il y a une corrélation d’environ 4% et que les dettes publiques au dessus de 90% sont plus proches en moyenne de 150%, ça pourrait expliquer cette baisse à 2,1% de croissance en moyenne. Non ?
Bonjour,
je vais peut-être être prétentieux, mais ne passe-on pas rapidement de corrélation à causalité ? Ne peut-on pas dire aussi qu’un déficit de croissance creuse la dette ? Où qu’un pays « en difficultés » a une faible croissance et un déficit qui creuse la dette ?
Je suis d’accord avec ton point de vue. Corrélation ne veut pas pas dire causalité, et si causalité il y a, encore faut il en trouver le sens…
Je ne savais pas que les politiques économiques étaient édictées par des scientifiques? je croyais que c’était le peuple qui dirigeait en démocratie ? C’est d’ailleurs la raison pour laquelle la dette ne cesse d’augmenter quelles que soient les conséquences à long terme, « long terme »: notion dont le peuple n’a pas conscience.
C’est du second degré, ou bien???
L’évolution de l’endettement est une chose, mais se pose-t-on la question de savoir à quoi a servi cet endettement, de l’investissement productif où le financement d’un conflit armé ? Cette composante est pour moi fondamentale dans l’analyse. De plus l’endettement a-t-il eu lieu en monnaie nationale, dans ce cas l’inflation peut permettre de résorber une partie de la dette, ou en devises étrangères ?
Est-ce que quelqu’un a ajouté les 10 années depuis 2009 pour voir si ça change le résultat ?
Que se passe t’il si on regarde d’un côté les années 46 à 75 et d’un autre côté les années 76 à nos jours ? (je ne suis pas économiste du tout, mais comparer la croissance pendant les 30 glorieuses (rattrapage de WW2 etc.) avec l’époque suivant ne me semble pas pertinent.
Est-ce que ce genre de chose existe sur Internet ?
bonjour
je suis toujours surpris qu’excel soit utilisé pour faire des statistiques, c’est cool, on peut faire des jolie graphiques à l’arrache, placer des photos, briller en reunion avec des utilisation abscons, faire semblant d’utiliser des fonction mathematiques poussé. Mais ce n’est pas le meilleur outil pour ne pas faire d’erreur. Une base de données et des requetes SQL avec R permet de ne pas tricher en masquant des lignes, modifier des couleur pour tricher, changer d’échele « parcequecam’arrange » ™ ® et la valeur à -7,4 j’aimerais qu’elle soit a +12,7 car la courbe est plus jolie -> hop je corrige la case que je masque en suivant.
Je trouve que le plus incroyable est encore que l’article de Reinhart et Rogoff n’ait pas été rétracté, et qu’aucune mention de sa fausseté ne soit même mentionnée sur le site de la revue: https://www.aeaweb.org/articles?id=10.1257/aer.100.2.573
Les deux auteurs ont fait une réponse à Herndon, Ash and Pollin, mais dans le New York Times !
Pingback: عن الأرقام في الاقتصاد والخطة الإنقاذية | الإنسان
Bonjour David,
J’aurais du coup une question de relativité générale : quelle déformation faut-il appliquer à l’espace-temps pour qu’un article paru en 2010 ait « une influence majeure sur les politiques d’austérité » (je cite) sachant que ces politiques d’austérité commencent avec le second choc pétrolier, dans les années 1970 (Reagan aux US et Thatcher au RU typiquement) et n’ont jamais été remises en cause depuis (dans le sens où il n’y a pas eu de politiques économiques vraiment différentes) ? En France, le fameux « virage de la rigueur » de Mitterrand a lieu en 1983, bien avant l’article ou les critères de Maastricht. Du coup, sans nier que cet article ait été repris, je doute qu’il ait eu le moindre impact sur les politiques économiques.
Autre sujet, mais aussi d’actualité dans les politiques économiques : il est assez facile de montrer qu’il n’y a pas de lien empirique entre la flexibilité du marché du travail et le chômage. Dit autrement, flexibiliser le marché du travail ne crée pas d’emploi (cela peut dans certaines situations très spécifiques, mais ce n’est pas systématique et ce n’est pas du tout le premier facteur de création d’emplois). Pourtant, depuis, de nouveau, un grand nombre d’années, le levier massivement utiliser par les pouvoirs publics pour lutter contre le chômage est … la flexibilisation du marché du travail.
En économie, il est assez facile de multiplier les exemples d’incohérence entre les travaux scientifiques et les décisions publiques (on parle du ruissellement et des premiers de cordées ?). Alors l’article et la vidéo sont très bien, ce n’est pas mon point, mais il est plutôt fallacieux de dire / titrer : « Les politiques d’austérité : à cause d’une erreur Excel ? » Là où il me paraît important de souligner cela, c’est que si on pense que les politiques se justifient par des articles scientifiques, alors on pourrait croire que pour « changer notre monde », il faudrait et suffirait de produire de la science rigoureuse, de qualité et de diffuser cette science. Et non, pas du tout et c’est bien le problème auquel nous sommes confrontés aujourd’hui : comment influer les politiques publiques ? Comment faire en sorte que ces politiques profitent au plus grand nombre (sans pondération dans le calcul « du plus grand nombre », c’est à dire sans pondérer un individu par son patrimoine) ?
Là où la problématique devient critique, c’est lorsqu’on parle d’écologie. De nouveau, il y a un assez gros consensus scientifique sur l’état de la planète et la pente sur laquelle nous sommes. Et pourtant, ce consensus ne se traduit pas du tout politiquement (au niveau des politiques publiques, de nouveau, sinon oui, ça se traduit par la signature d’accords qu’on s’empresse de ne pas respecter).
Donc non, il n’y a malheureusement pas de lien entre la science et la décision publique. Nous ne sommes pas vraiment dans la cité idéale de Platon, avec des « philosophes rois » (qu’on pourrait aujourd’hui élargir aux scientifiques vu que dans la Grèce antique, on distingue peu les deux, les scientifiques étant aussi philosophes).
« A moins que, dis-je, les philosophes n’arrivent à régner dans les cités, ou à moins que ceux qui à présent sont appelés rois et dynastes ne philosophent de manière authentique et satisfaisante et que viennent coïncider l’un avec l’autre pouvoir politique et philosophie ; à moins que les naturels nombreux de ceux qui à présent se tournent séparément vers l’un ou l’autre n’en soient empêchés de force, il n’y aura pas, mon ami Glaucon, de terme aux maux des cités ni, il me semble, à ceux du genre humain. » (La République, Platon).
Merci pour cette vidéo encore une fois très intéressante, même si ce n’est pas du tout mon domaine d’intérêt. Pour avoir travaillé quelques années dans un laboratoire de recherche (pas de le domaine de l’économie), j’ai eu l’occasion de voir à l’oeuvre le comportement scientifique de certains « chercheurs ».
Le mode de fonctionnement actuel de la recherche scientifique est pas mal basé sur le principe des « castes ». Certains chercheurs reconnus dans leur domaine sont considérés comme au-dessus des autres et seront très rarement contredits par leurs homologues. Tout le monde se connaît dans un domaine donné et on n’a pas envie de dire du mal de ses collègues, pour diverses raisons. Donc un chercheur bien considéré qui dirait une bêtise (plus ou moins importante) dans un article ne sera très probablement dénoncé par personne. Le problème c’est que ça accentue encore plus l’égo de ces « pontes ».
L’effet pervers c’est qu’ils vont de plus en plus avoir l’impression de détenir la vérité absolue. Et donc quand ils vont vouloir qu’un de leur article aille dans le sens des arguments qu’ils soutiennent, ils feront tout pour que ça se produise. Quitte à « omettre » ou « transformer » quelques données pour que le résultat aille dans leur sens… C’est un véritable cercle vicieux qui se met en place, au total détriment de la Vérité scientifique. On est là très très loin du fonctionnement attendu de nos institutions de recherche ! Et malheureusement en une grosse dizaine d’années j’ai pu constater la montée en puissance de ce fonctionnement. Certains chercheurs aux égos surdimensionnés en deviennent d’ailleurs inbuvables humainement. D’ailleurs en tant qu’ingénieur rigoureux et toujours prêt à se remettre en question j’ai décidé de quitter ce milieu par écoeurement.
Dans le cas de cet article dont tu parles, j’ai très clairement l’impression que ces chercheurs ont juste cherchés à démontrer une conclusion qu’ils avaient définis à l’avance. Vu leur niveau ce n’est pas possible qu’ils ne soient pas rendu d’erreurs aussi grossières. 2-3 outils statistiques de base suffisent pour démontrer que leur argument principal ne tient pas la route ! Ce n’est pas comme si une petite erreur complexe à détecter avait eu une grosse influence. A ce point c’est clairement de la manipulation pure et simple des données et calculs pour arriver au résultat qu’ils voulaient. Comme ce n’est pas la première fois que je vois ça, je n’ai personnellement aucun doute !
Pingback: Démarche scientifique et transparence de l’information | le bloc de vinboc
Excellente vidéo et non moins excellente conclusion. J’avoue qu’avec mes maigres connaissances en économie (voire inexistantes), j’aurais plutôt parié sur un lien de causalité inverse par rapport à celle du commissaire européen : une faible croissance entraine la nécessité de recourir à de l’emprunt pour y pallier. Mais bon, comme de toute façon le lien n’est pas établi, inutile de se battre pour savoir dans quel sens 🙂
Bonjour David, bonjour à tous,
Tout d’abord je vous conseille de regarder le documentaire (Oscar du meilleur documentaire en 2011) Inside Job, il y est notamment question de la connivence entre les élites universitaires (Harvard, Yale…) et les décisionnaires financiers (FED, Secrétariat d’Etat eu Trésor, FMI…).
Avant même de commencer à analyser des données il faut se demander ce que sont ces données:
PIB selon quel critères: Incluant trafic de drogue et prostitution comme les données d’Eurostat? PIB en parité de pouvoir d’achat? En $? En base 100 quelle année?
Dette: Dette publique? Dette d’Etat? En incluant la dette des services publiques? Des entreprises publiques? En $? Etc..
Pays: Pas de Chine, de Russie qui sont de grandes puissances économiques. Pas d’Estonie qui a une dette très faible. Comment sont choisis ces pays? La sélection est elle représentative ou biaisée?
Après sur la méthodologie d’analyse en pourrait en dire beaucoup. Mais j’ai déjà énormément buggé quand David annonce que ces moyennes sont regroupés en « trentile » cela n’a aucun sens si ce n’est d’aboutir à ce que les chercheurs veulent démontrer.
On passera le R carré de presque 0. Une « erreur » de transcription… Une « erreur » de plage de donnée… Je laisse ça aux scientifiques que vous êtes.
Tout cela cumulé fait beaucoup pour penser que cela résulte du hasard. Surtout quand les chercheurs en question ont travaillé tous les deux pour le FMI et que Carmen Reinhart a travaillé chez Bearn Stearns l’une des entreprises financières les plus affectées par les subprimes pendant le crise de 2007-2008. Entreprise renfloué par la FED avant d’être racheter par JPMorgan avec l’aide de l’argent public.
Je vous conseille une petite filmographie pour compléter ludiquement le sujet:
-Inside Job (documentaire)
-Too big too fail, débâcle à Wall-Street
-The Big Short
-Margin call
-Goldman Sachs la banque qui dirige le monde (documentaire ARTE)
Bonne continuation,
Ayant donné des cours d’Excel et modestement initié des etudiants a l’analyse des données, je suis content de constater mon premier conseil n’était pas mauvais : avant de partir dans les calculs commencez par faire quelques nuages de point. Merci pour lexcellente qualité de vos vidéos et l’esprit qui les fait exister.
Bonjour, comme je viens de découvrir la critique du modèle d’analyse linéaire (cf. I. Ermakoff, “La causalité linéaire: Avatars et Critiques” ), je me permets de te faire la réflexions suivante (en complément de toutes les critiques que tu as déjà faites).
Je trouve problématique de comparer un niveau de dette à une croissance sans intégrer que le lien, s’il existe, s’inscrit dans une séquence du type : création de la dette en année n, effet sur la croissance en années n+x. Pour le dire simplement, l’effet d’un investissement ne s’observe pas sur l’année de l’investissement, ni sur une moyenne d’un nombre indéterminé d’années.
Cela permettrait de répondre à la question : « la dette génère-t-elle de la croissance ? », même si on pourrait aussi étudier l’effet de la croissance sur la dette (sur le mode, « la croissance est-elle une condition de l’endettement ? »).
Il serait alors pertinent de faire une analyse séquentielle (cf. H. MacIndoe et A. Abbott, Analyse de séquences et techniques d’appariement optimal pour les sciences sociales) et je me dis que cela pourrait t’intéresser d’un point vue heuristique.
Les liens :
– https://sociology.wisc.edu/wp-content/uploads/sites/466/2019/08/2016-Ermakoff-Causalite-lineaire.pdf
– https://www.jstor.org/stable/204500?seq=1 (ou en Français dans Demazière D. et Jouvenet M., Andrew Abbott et l’héritage de Chicago, EHESS, 2016)
Parfait : passionant et clair. Merci. Juste une remarque et une info.
Vous illustrez ce que j’appelle « le raisonnement par étiquette », c’est-à-dire où un nom remplace le… raisonnement, justement. « Ah, mais si cet article vient de duschmoll, c’est qu’il est excellent ! » Nous ne sommes effectivement plus très loin de l’obscurantisme. Cela devient même épidémique et pas qu’en économie, en effet.
Des chercheurs en biochimie me disaient que toutes le expériences relatées dans des revues scientifiques (même de renom) ne sont – volontairement cette fois ( ?) – pas reproductible : c’est la crainte du plagiat qui en est la cause. Dans le monde de la recherche appliquée, c’est aussi la guerre… Fermons les yeux !
Merci encore pour vos vidéos !
Merci pour ce travail, rigoureux comme d’habitude. Comme certains commentaires en font déjà part, il faut (je viens de le faire) exactement 4 clics pour obtenir le nuage de points (grouth vs debt) sous Excel dont l’aspect peu corrélé saute aux yeux. Je pense franchement sur l’escroquerie intellectuelle ET le biais de confirmation.
Pingback: La transition écologique sera vaine sans "transition économique" - Blog Reculs - Rémi Borel
Excellent sur tous les plans! Ce qui m’interpelle, dans la notion de dette, c’est qu’on ne sépare pas l’emprunt destiné à financer de l’investissement, donc avec potentiellement des retombées positives, de la dette comblant un écart entre les dépenses (toujours excessives, bien sûr!) et les recettes… D’autant que le dogme libéral conduit nos politiques à afficher des baisses d’impôt (et donc de recettes) en arguant qu’elles ont des retombées fortes sur la croissance, ce qui semble assez difficile à démontrer. La crise du Covid actuelle montre bien que le défaut d’investissement sur l’hôpital public, la recherche, et la santé de façon générale, conduit à un coût faramineux! La Grèce a bien du mal à se redresser, alors même qu’on l’a fortement incitée à investir massivement pour les Jeux Olympiques, investissements difficiles à amortir, encore plus si le tourisme se met au point mort pour un moment…
En tous cas, merci pour cette vidéo passionnante, qui montre bien à quel point il faut être méthodique et rigoureux lorsqu’on participe de près ou de loin à la décision politique… Cela souligne aussi la fragilité de nos systèmes statistiques, souvent en retard de quelques métros par rapport aux réalités, et un gros travers de nos instances dirigeantes: « LE chiffre, donnez-moi LE chiffre qui résume tout, je ne veux pas lire votre document, résumez-le en 10 lignes… » Comme si un pays, une économie, ou une ville, pouvait se résumer en un chiffre!!!
Bonne continuation…
Où ça, des « politiques d’austérité » ??
Merci David ! 😀 Cette histoire est « juste » incroyable… Quelle leçon ! :O Je retiens de l’exercice qu’il est à reproduire dans nos chères facs et écoles ! 🙂 Perso, en 2010-2012 j’avais déjà été convaincu par D. L. Donoho qui relayait haut et fort que : « Good science is reproducible science! » (tout en codant exclusivement en Matlab… ;D). La déferlante Python me semble encore avoir enfoncé ce clou. Bref, ça progresse. Mais tous les domaines de recherche ne sont (malheureusement) pas égaux. Par exemple, si en « traitement d’images » vous allez reproduire assez facilement un algo (merci et bravo à « IPOL » au passage ! ;D), en « chimie » ou en « biologie », je vous souhaite bon courage pour reproduire des courbes dont chaque point représente minimum 1/2 journée de travail (TP, etc.). Bref, si la confiance c’est le contrôle, parfois le temps manque cruellement… :$…
You can certainly see your skills in the work you write.
The sector hopes for more passionate writers like you who aren’t afraid to say how they believe.
All the time follow your heart.
Bonjour,
Voici le lien vers l’interview de Rogoff par le Nouvel Obs en 2010.
https://web.archive.org/web/20101208063629/http://laviedesaffaires.blogs.nouvelobs.com/archive/2010/09/29/la-crise-des-dettes-souveraines-n-est-pas-finie.html
L’erreur vient peut-être d’une mauvaise maîtrise d’Excel par nos deux chercheurs.
Supposons que dan la cellule B980 on a la formule «=MOYENNE(B3:B979)», si on insère une ligne avant celle de la cellule de la formule (qui va passer en B981), cette formule ne se mettra pas automatiquement à jour et l’on aura en B981: «=MOYENNE(B3:B979)». Donc, si l’on saisit quoi que ce soit dans cellule B981 de la ligne inséré (ligne 980), ça ne sera pas pris en compte dans la formule en B981.
Les deux chercheurs devaient ignorer cette particularité d’où «l’omission» des cellules du bas du tableau dans leur formule. Pour éviter cela, ils auraient dû ajouter une ligne vide en bas du tableau avant la formule, intégrer la cellule de cette ligne vide dans la plage de données de la formule puis n’insérer de nouvelles lignes seulement avant cette ligne vide; ainsi la formule se serait ise à jour automatiquement.
Je vais réitérer mon commentaire de youtube, utiliser python sur jupyterlab avec pandas, et matplotlib, c’est mon quotidien et j’apprécie de voir une chaîne comme la tienne l’utiliser. Ça fait du bien.
Vive les logiciels libres 😉
Pingback: Un peu de Méthode dans ce monde de brutes... - ISLEAN
Pingback: C'est trop compliqué... - Allocation Climat