 Vous connaissez le canapé Söft ? La commode Utrad ? L’étagère Hång ? L’armoire Muskydd ? Le mixeur Skymfor ? La poële Kukväde ? Le placard Klöstig ? Le circuit Rundering ? La table Oljulstad ? Les rideaux Lykofåtsly ? Le bureau Håkmanedfol ? La chaise Sjärganskig ?
Vous connaissez le canapé Söft ? La commode Utrad ? L’étagère Hång ? L’armoire Muskydd ? Le mixeur Skymfor ? La poële Kukväde ? Le placard Klöstig ? Le circuit Rundering ? La table Oljulstad ? Les rideaux Lykofåtsly ? Le bureau Håkmanedfol ? La chaise Sjärganskig ?
Eh bien contrairement aux apparences, ces noms ne font pas partie du véritable catalogue Ikea ! Ils ont été fabriqués automatiquement par un algorithme qui s’inspire de vrais mots suédois pour en créer de nouveaux, qui « sonnent suédois » mais n’existent pas dans cette langue.
Les habitués de ce blog auront reconnu la méthode que j’avais utilisée il y a quelques semaines pour vous proposer ma machine à inventer des mots, au sujet de laquelle j’avais fait cette vidéo, que je vous remets pour ceux qui ne l’ont pas vue
[youtube=http://www.youtube.com/watch?v=YsR7r2378j0]
Suite à la vidéo, j’avoue avoir été surpris par le nombre de personnes qui me demandaient le code source ! Il se trouve que je l’avais mis en partage sur le billet précédent, mais sans trop faire gaffe à la qualité de ce qu’il contenait.
Vu l’enthousiasme général et suite à un certain nombre de questions et suggestions, j’ai décidé de récrire une version un peu plus propre du code, et de la partager avec vous.
Parmi les nouveautés de ce code, j’ai surtout inclus plus de langues, grâce à une excellente source : les dictionnaires du package hunspell, merci à Samuel pour cette idée brillante ! (ici l’archive contenant les dictionnaires que j’ai légèrement adaptés)
Dans le cas du français, on peut faire la comparaison avec le dictionnaire que j’avais utilisé pour faire ma vidéo. En fait ce dernier n’en était pas vraiment un puisqu’il s’agissait plutôt d’un corpus de mots issus d’une analyse automatique des livres du projet Gutenberg. Ce corpus contenait donc beaucoup de mots au pluriel, ou bien de verbes conjugués à tous les temps, ce qui influençait pas mal les mots que j’avais obtenu dans la vidéo. Autre différence, les livres du projet Gutenberg étant supposés être du domaine public, on trouvait pas mal de vieux textes, ce qui donnait à mon avis ce côté sympathiquement « vieillot » des mots que j’avais générés.
Avec le dictionnaire français de hunspell, c’est un chouilla moins fun je trouve, mais ça marche bien quand même.
Voici quelques mots « français » fabriqués aléatoirement :
bilectique, pulablote, cyclisale, pluminer, gréricodire, tacatraptée, bardemper, cyclisale, gulatrie, extrabler, capapente, etc. (plein d’autres mots ici)
Grâce à hunspell, j’ai pu facilement étendre l’analyse à d’autres langues comme
l’espagnol,
cebilleño, diznerón, perador, vitazar, malúrda, menjez, cozonar, realsargados, etc. (plein d’autres mots ici)
l’italien,
tiviatote, oritace, ingivolosi, cappidero, stezzano, crettoble, revanazio, nenteggiando, etc. (plein d’autres mots ici)
le hongrois,
kérmegy, szapolt, hiszó, ujjóbbrak, csipitkolge (plein d’autres mots ici)
et donc surtout…le suédois (plein d’autres mots ici) ! Ikea n’a qu’à bien se tenir !
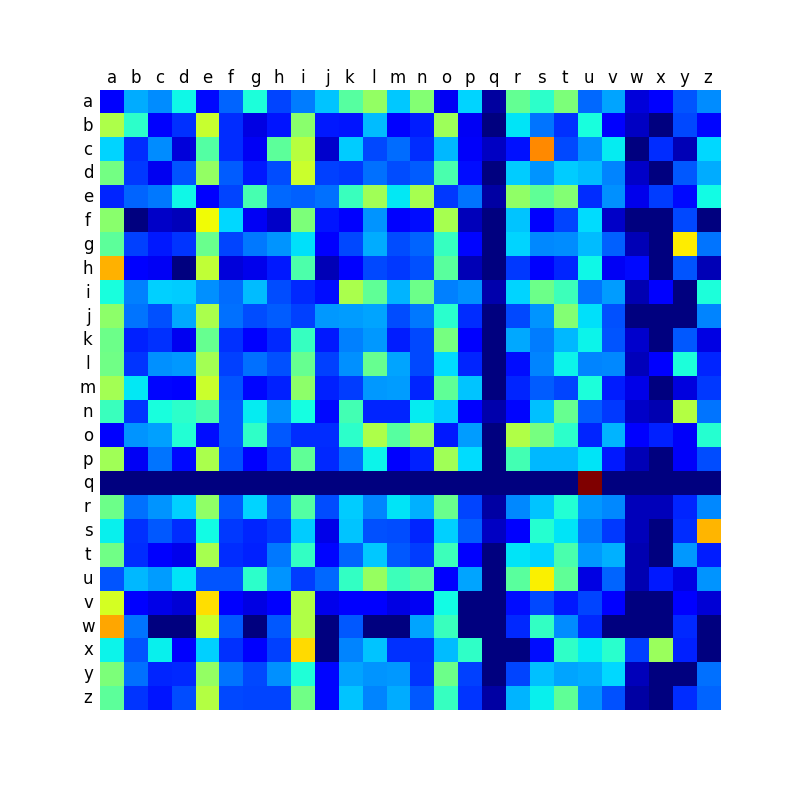
Ci-dessous, vous trouverez une comparaison des matrices de transition des différentes langues, et qui montre que certaines langues sont plus contrastées que d’autres. Comme je le disais dans mon premier billet sur le sujet, les mots anglais créés par la machine sonnent relativement mal, et je pense que c’est à relier avec le fait que la matrice est peut-être moins contrastée que dans les autres langues, ce qui conduit à produire des mots plus aléatoires et moins typés.
Mais je vous mets tout en téléchargement pour que vous puissiez vous faire votre idée ! (ICI LE CODE SOURCE)
Français
 Anglais
Anglais
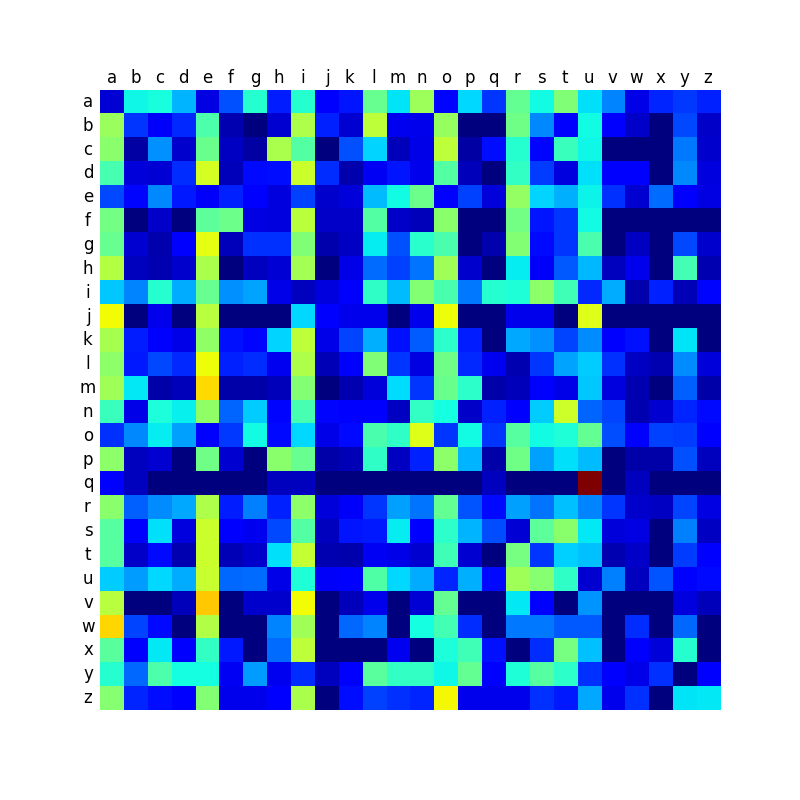
Suédois
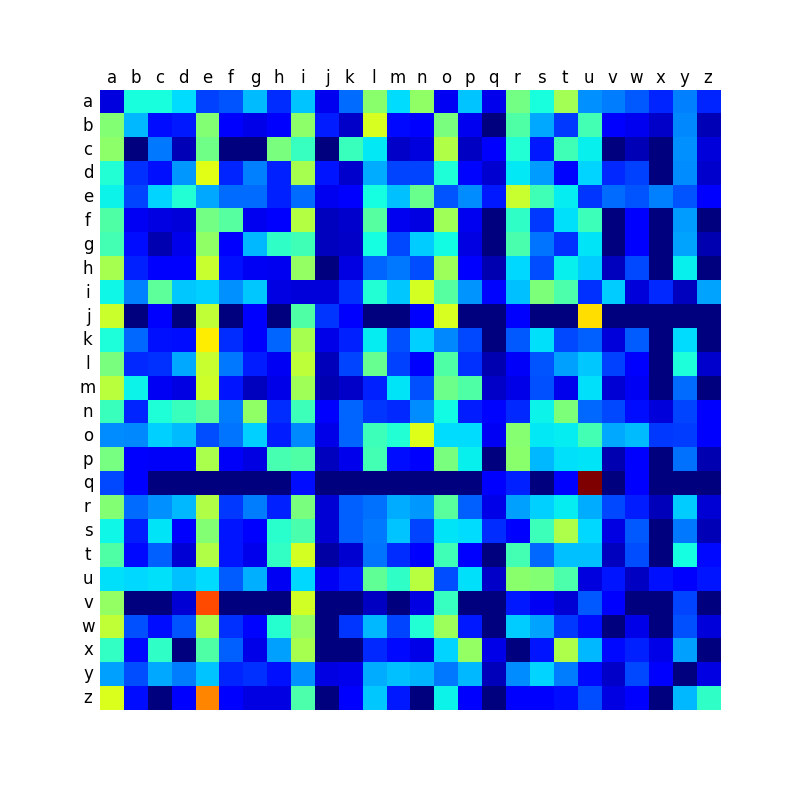
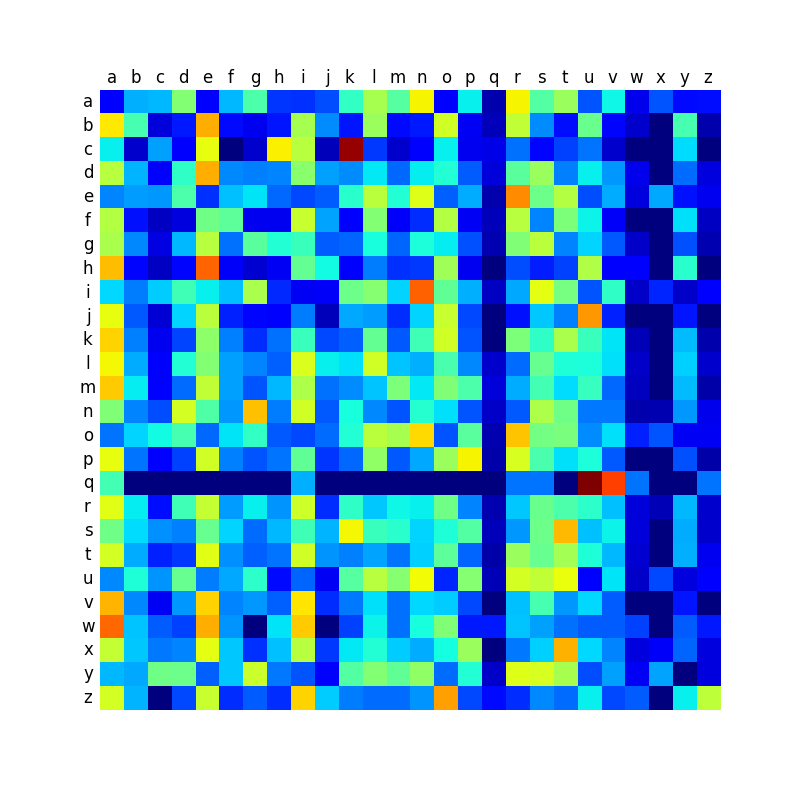
Italien
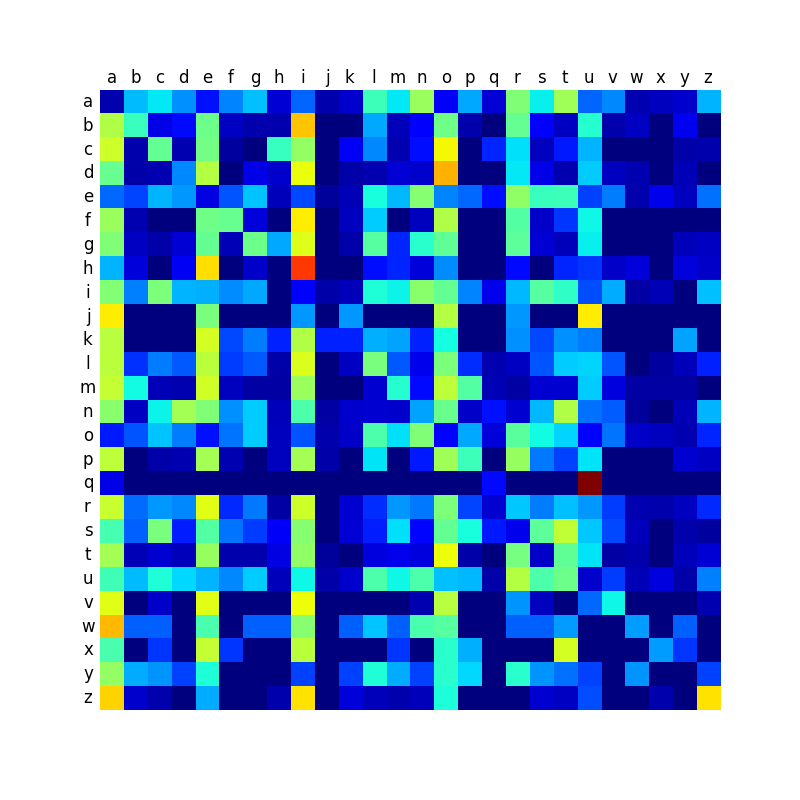
Espagnol
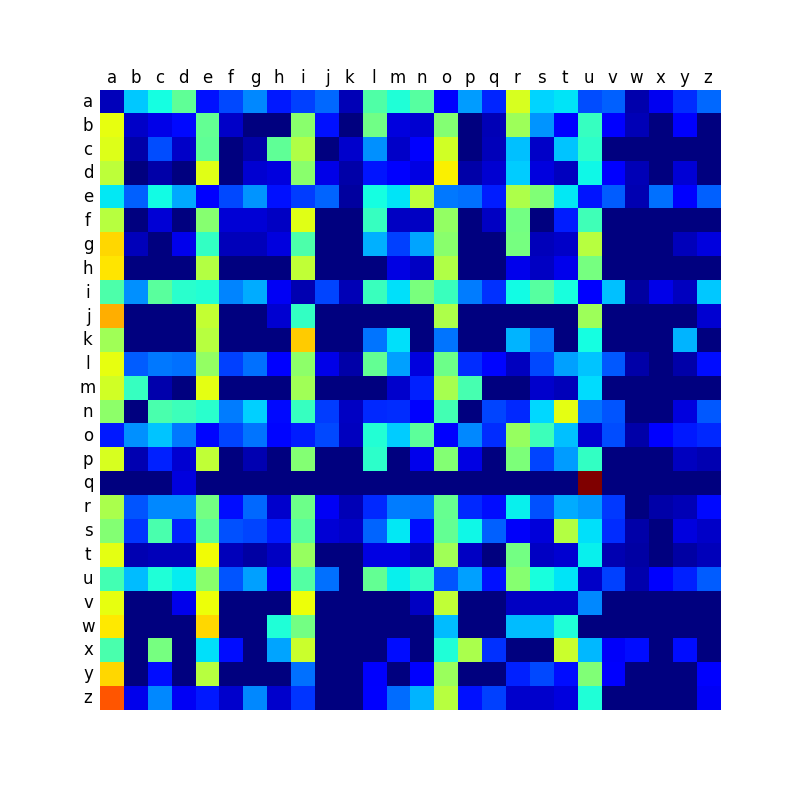
Hongrois



45 Comments
J’adore ! Attention toutefois les mots aléatoires évoquent parfois des mots existants… et pas les plus polis !! 🙂
Kukväde par exemple… Il ne manque qu’un R au bout pour en faire un « temps de bite » !!! 🙂
Ah ça ne fonctionne pas chez moi … il me trace le graphique (avec quelques warning) mais refuse de me faire des mots. Un problème de version 32 / 64 bits ?
Essaye de rajouter ces lignes après les imports pour forcer l’encoding, ça devrait fonctionner ensuite:
import sys
reload(sys)
sys.setdefaultencoding(‘ISO-8859-1’)
Hello… parlant moi-même suédois, je trouve que les mots ainsi générés ne « font pas trop suédois ». Alors que ça semble mieux marcher en français… Est-ce que l’ordre de la chaine de Markov devrait varier avec la langue ?
En tout cas, je soupçonne fortement que ça ne marchera pas avec les langues sémitiques….
Pingback: La machine à inventer des mots, version ...
Regarde http://fantasynamegenerators.com/ . Dommage qu’ils ne donnent pas leur code … Par contre le tien du devrais le mettre sur GitHub 😉
🙂 prout
Pingback: Actualités - Dossiers à lire | Pearltrees
Merci pour cette présentation ludique, et notamment la super introduction aux chaînes de Markov !
Les « pseudo-mots » – c’est comme ça qu’on les appelle – sont fascinants car ils allient le plaisir très oulipen de jouer avec des sonorités cocasses à l’utilité scientifique. Quelques précisions à ce propos justement :
Les pseudo-mots sont abondamment utilisés par les chercheurs en linguistique qui étudient comment le langage est acquis durant l’enfance, ou comment le cerveau traite et produit des mots. Des expériences utilisant des pseudo-mots ont permis par exemple de montrer que les enfants internalisent des règles assez complexes sur les structures phonétiques d’une langue avant même de commencer à parler, et ne se contentent donc pas simplement d’apprendre les mots qu’ils entendent par coeur. Les pseudo-mots permettent également de distinguer les mécanismes cérébraux liés au sens des mots (sémantique) de ceux qui en analysent la structure (phonétique et morphologie).
Les linguistes utilisent différentes méthodes pour générer des pseudo-mots, y compris les chaines de Markov. Mais comme ils utilisent à la fois des vrais mots et des pseudo-mots dans leurs expériences (afin de les comparer) et qu’ils souhaitent contrôler précisément la nature des différences entre ces deux groupes de mots (comme la longueur, l’homonymie, la fréquence des syllabes, la proximité avec d’autres mots, etc.), ils partent en général de la liste des vrais mots qu’ils utiliseront dans leur expérience et les transforment selon des règles bien définies.
Deux générateurs de pseudo-mots utilisés par les chercheurs :
Wuggy : http://crr.ugent.be/programs-data/wuggy
WordGen : http://www.wouterduyck.be/?page_id=29
Pour rebondir sur votre commentaire, un billet trouvé sur le Webinet des curiosités au sujet d’études faites avec des pseudo mots sur des bébés : http://webinet.cafe-sciences.org/articles/les-bebes-genies-de-la-statistique/
Pour résumer, le probabilité d’enchaîner certains phonèmes varie d’une lange à l’autre. Les bébés vont instinctivement estimer si une suite de sons est susceptible de constituer des mots de la langue parlée par son entourage. Fascinant : http://webinet.cafe-sciences.org/articles/les-bebes-genies-de-la-statistique/
Pourquoi pas un générateur de nouveaux prénoms?
Salut je travaille sur un projet dans lequel j’aurait besoins de tes données sur les enchainements de lettres mais ton tableau(sur mon pc) je n’arrive pas a différencier les cases noirs (sans AUCUN enchainement(je précise parsque c’est important pour mon projet)) des cases bleu foncé. As tu les données sous forme de chiffes? ou uniquement le tableau?
Si tu as les données peux tu s’il te plait me les envoyer?
Je confirme que les mots hongrois font assez hongrois. Tök jo !
Persze 🙂
j’ai beaucoup aimée votre machine à inventé des mots vous pensez que ça existe en Japonais ?
Petite question idiote d’amateur ignorant: on fait quoi avec le code pour générer des mots???
le fichier a un nom qui finit en .py, donc … langage python.
Comme j’ai beaucoup aimé l’idée, je m’en suis inspiré pour créer une version de la machine dans le langage R (avis aux amateurs: https://github.com/GregVial/WordGenerator ). J’ai développé une version française, mais aussi une russe, et cette dernière me parait encore plus convaincante!
Merci pour l’idée de la machine à inventer des mots. Je l’ai reprise pour mon cours d’initiation à LabVIew à mes étudiants de master. Dans mon fascicule de TP, je les renvoie vers ton blog et ta vidéo. J’espère contribuer modestement à augmenter le nombre de vue et à faire connaître tes vidéos et ton blog.
Quelqun peutm’expliquer cmment on utilise la machine svp? J’y comprend rien lá:/
Le code tente d’utiliser un encoding sur un octet mais les données de « data » sont en utf-8.
Pour utiliser le code j’ai tout repassé en raw bytes.
C’est marrant, parmi les mots italiens générés, il y a « castratore »… castrateur en français 🙂
ça ne marche absolument plus
Bonjour,
Cette « machine » m’intéresse énormément, mais je n’y connais absolument rien en python. En fait, je fais des idéolangues (vous savez, ces langues construites telles que l’espéranto ou le quenya de Tolkien), et je me disais que ce serait un super moyen de systématiser la création de mot quand on en a créer suffisamment, et que l’idéolangue à sa propre « identité phonétique ». Du coup, j’aimerais bien trouver un moyen d’adapter la machine à n’importe quel lexique de mot, mais voilà, je suis idéolinguiste, pas informaticien. J’ai bien téléchargé winpython, mais une fois sur le logiciel, je ne vois pas ce que je dois faire.
Est-ce que quelqu’un pourrait m’expliquer ?
En vous remerciant d’avance.
Bonjour
Je devrais pouvoir vous aider… envoyez moi un mail a greg_vial at hotmail.com et on discutera de votre projet!
A bientôt
Grégory
Bonjour !
J’aimerais travailler sur un projet qui ressemble au votre, ou en tous cas pose des problèmes similaires. Je suis également très intéressé par votre activité d’idéolinguiste… Serait-il possible d’en discuter ?
joseph.quaredec at gmail.com
En vous remerciant par avance !
Super article, j’avais gardé en tête ta vidéo sur la machine à inventer des mots, c’est encore plus poussé !
J’aimerais écrire un programme qui convertisse une suite de chiffres en mots français selon la méthode majeure. (pour la mémoriser plus facilement)
Pour ça le plus simple serait d’avoir un dictionnaire phonétique. Quelqu’un sait où je peux en trouver un ?
Merci d’avance !!
Ce projet est super interessant, mais je comprend pas pourquoi la liste des mots est toujours la meme ?
David,
le code source n’est plus présent dans le lien suivant :
http://www.science-etonnante.com/WordsMachine/machine.py
peut-être le fichier py a été supprimé si hébergement mutualisé ?
Peux-tu remettre le code quelque part peut-être zippé ?
Merci beaucoup
Emanuele
David,
j’ai une question qui concerne l’approche utilisé.
En fait la matrice obtenue considère la probabilité qu’un caractère soit suivi par un autre.
Cela suppose que la probabilité d’apparition ne soit pas liée aux caractères précédents, chose qui est vraie seulement dans une première approximation.
Une idée plus avancée pourrait être de considérer qu’il y ait une relation de cause avec le caractère précédent, mais aussi avec le caractère encore précédent. On aurait donc deux matrices.
La deuxième matrice aurait donc la même forme. Le caractère « a », par exemple aurait une certaine probabilité qu’il soit suivi par n’importe quel autre caractère, mais qu’il soit encore suivi par le caractère « a » deux caractères plus loin, comme dans « anatomie ».
La question que je pe pose est la suivante : comment combiner les deux matrices ? Ou peut-être il n’y a pas moyen de les combiner et le processus de calcul doit donc se faire en deux étapes ?
Comment tu vois la chose ?
Emanuele
Merci beaucoup pour ton travail exceptionnel de divulgation scientifique !
Bonjour Emanuele,
Ce que tu cherches à faire, c’est donner de la mémoire à une chaine de Markov.
C’est réalisé classiquement et très simplement en construisant une matrice de transition d’une lettre à une autre, mais d’une paire de lettre à une lettre. Au lieu d’avoir une matrice de 26 lignes et 26 colonnes, on a donc 26×26=676 lignes par 26 colonnes.
On peut donc théoriquement donner encore plus de mémoire à notre chaine de Markov en utilisant des triplets de lettre, des quadruplets, etc. Mais le nombre de lignes de la matric explose alors exponentiellement avec la taille de la mémoire !
Merci Ous pour cette réponse pertinente.
A vrai dire j’avais imaginé une chose similaire, mais encore plus gourmande en calcul, de créer donc une matrice par paire de lettre avec 26×26 lignes et 26×26 colonnes. Cela ne m’avais pas convaincu car cela aurait donné toujours des mots avec un nombre paire de caractères. Puis on aurait eu un problème d’analyse avec des mots contenants un nombre impaire de caractères. Ta solution est assez intéressante avec du coup une matrice pas carrée.
Au final une simple matrice 26×26 a le désavantage de produire potentiellement des séquences de caractères inexistantes dans une langue donnée. Par exemple « s » a une certaine probabilité d’être suivie par « p » (spécialité…) et « p » a quand même une certaine probabilité d’être suivi par « s » (psychologie..). Cela donnerait une probabilité pas négligeable de générer « sps » qui n’existe pas en langue française (enfin pas sûr car je ne suis pas français 🙂
Une autre idée pour utiliser une grosse matrice 676×676 pourrait être d’analyser l’espace » » comme s’il s’agissait d’un caractère et cela pourrait résoudre le problème du nombre pair des mots puis celui de la fin du mot, car il y aurait certains caractères qui ne seraient jamais suivi d’un espace. Au lieu d’analyser un dictionnaire on analyserait un texte entier avec suppression des points, virgules et signes de ponctuation remplacés par un espace, puis remplacement des doubles ou triples espaces par un seul. Et avec la génération des espaces on produirait un texte entier au lieu de produire que des mots isolés.
Ça s’implémente très bien avec un cube de 26*26*26 afin d’éviter les séquences inexistantes en français, j’avais reproduit le code de David en R et ça fonctionnait nickel: https://gregv.shinyapps.io/WordGenerator/
Il est aussi possible d’implémenter le programme avec une chaine de Markov de profondeur 2, voire 3, et pour cela le package python markovify est tout à fait indiqué, il te le fait en deux coups de cuiller à pot.
Merci Gregory, de mon côté je viens de développer en php, avec la matrice 677 x 26 (couple de caractères vers caractère) en analysant les 600 mots les plus utilisés en français séparés par un espace.
Cela me donne un résultat correct :
lain
épar
dédecourespère
hieur
trece
proposembraiter
malment
plandrouve
roigneleurne
attemincider
rouloir
…
C’est marrant car certains mots français qui n’étaient pas dans les 600 les plus utilisés (comme rouloir) ont été générés ex novo.
Et cela avec une matrice 19686×26 (profondeur 3->1), toujours à partir des 600 mots français les plus courants :
abande compagner lange fautre cole voir suit évite vieux façon rapper amourire conne tentier préponsieux françaisonne souvrire imposer achevaloire gueul toute professibler inquiéteste faiter reposer dée arre mari matin chéritéral clieu doute danser résole venir propre arme papa payer oser sournal libre avion putaire poussir resser place part droiter apper tire minute cher déchien ciel arrander mer mettre sièce… etc etc…
Le résultat est meilleur, mais on y trouve beaucoup de mots français. Le calcul est quasi instantané.
Le fichier php (hors vocabulaire) fait 1500 octets.
Bonjour,
Les codes de David ne sont plus disponibles… Quelqu’un en aurait-il une copie ou un moyen pour les récupérer ? 🙂
D’autre part, j’aimerais travailler sur cette idée avec des dictionnaires de différentes langues, mais malheureusement je n’ai aucune idée de la manière dont on exploite la page des dictionnaires HunSpell donnée dans l’article (j’ai tenté de me renseigner sur le fonctionnement de GNU make mais ça dépasse de loin mes petites capacités…).
Quelqu’un pourrait-il m’aider ? Merci !!
Bonjour,
Serait-il possible d’avoir le code python qui n’est plus disponible à l’adresse URL fournie ?
Merci d’avance !
Idem pour moi 🙂
Je suis Moi aussi intéressé par ce générateur de mots aléatoires…
Ni les liens vers les dictionnaires mentionnés ni celui vers le code source ne fonctionnent.
Serait il possible d’y avoir accès ?
Merci d’avance.
Bonjour,
Vous pouvez retrouver le code source python grâce au site Internet Archive : https://web.archive.org/web/20151115020808/https://sciencetonnante.wordpress.com/2015/11/06/la-machine-a-inventer-des-mots-version-ikea/
Bonjour,
travail intéressant, les liens sont morts ?
Bonjour David
Tout d’abord pour la qualité de vos contenus et votre qualité de pédagogue : Une seul mot : BRAVO !
Je le permets de vous solliciter car il semble que les sources python sur la machine a créer les mot ne soient plus disponibles. Pourriez vous les remettre en ligne svp ?
Je pense que je ne suis pas le seul intéressé par cette ressource
Je vous remercie
Je les ai remis sur mon GitHub « scienceetonnante »
Bonjour,
J’ai pu trouver les fichiers du premier billet mais pas de celui-ci (nouveau code et dictionnaire tiré de hunspell), je ne sais pas si c’est voulu.
Merci pour ce travail très intéressant !
Pingback: La machine à inventer des mots [Vidéo] – Science étonnante